Those anecdotes in the advertising industry Series 9: A net to play Youtube deep learning recommendation system
This article has a total of 8370 words
Abstract: This is the main analysisYoutubeDeep learning recommendation system, drawing on model frameworks and excellent solutions in engineering to apply to real-world projects. First of all, we talk about the relationship between users, advertisers and video platforms such as Jiyin: that is, the platform to sell video resources as a commodity free of charge to users, while the user as a commodity paid to sell to advertisers, that's all. For the platform to achieve higher revenue, it must improve the efficiency of advertising conversion, provided that users are attracted to increase the length of time to watch video, which involves video recommendations. Because.YoutubeThe deep learning recommendation system is based onEmbeddingdo, so the second part is speakingEmbeddingFrom the appearance to the fire. The last net was doneYoutubeDeep learning recommendation system. The system is mainly divided into two segments, the first paragraph is to generate a candidate model, the main role is to the user may be interested in the video resources from a million levels of initial screening to a hundred levels, the second paragraph is a refined model, the main role of the user may be interested in video from a hundred levels to dozens of levels, and then sorted according to the degree of interest to form a user watch list. I hope that small partners interested in the referral system will be helpful.
Directory.
01 The relationship between users, advertisers, and jitter platforms
02 One-hotCodingWord2vecto Item2vec
03 YoutubeDeep learning recommendation system
1. YoutubeRecommended system background and challenges
2. The overall architecture of the algorithm
3. Build a candidate model
4. Fine-row model
01 The relationship between users, advertisers, and jitter platforms
If you're already familiar with the referral system and Embedding, you can skip directly to Chapter 3 to see the Youtube Deep Learning Recommendation System.
Here's a picture of the relationship between chicken thief advertisers, melon-eating users, and the jitter platform:
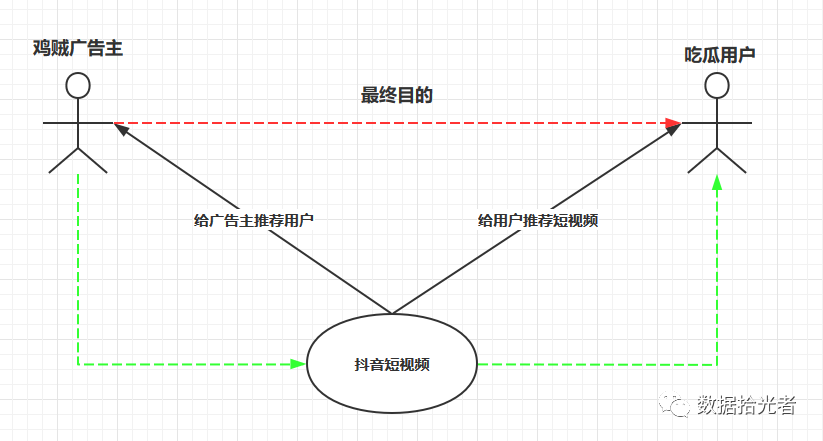
Figure.1 The relationship between users, advertisers, and jitter platforms
From a commercial point of view, the ultimate goal of chicken thief advertisers is to put ads to melon users, so that users have ad conversion, where the ad conversion may be click, download or even pay. But usually eat melon users generally have little interest in advertising, especially creative except. At this time the short video came, to the chicken thief advertiser said that my side can provide a platform to attract a large number of users, so that more users have ad conversion. In this way, advertisers directly to the user to advertise the road is not good to go, only through the curve to save the country, through the jitter platform interesting short video to attract users, and then while you look happy when cold brush to an advertisement. Because users spend more and more time on the shaker, the opportunity to expose ads is also more, there are always some people will click, download or pay for advertising, so indirectly achieved for advertisers to serve the purpose of advertising.
As a profitable company, the ultimate goal is to make more advertisers' money. To make more money from advertisers, you need to attract more users to the platform to watch short videos and have ad conversion behavior. But now the problem is that users because of individual differences so interest is diverse, some people like games, some people like cooking, some people like chicken soup, so the platform needs to recommend different types of short videos to different users, otherwise users brush two times feel boring to go.
Not only do you recommend videos that interest users here, but you also have to recommend the most appropriate ones. This is about the scarcity of exposure resources, how to understand this. Because users brush the sound of time is actually limited, in the user's limited time to firmly catch their eye, and then it is possible to let users have a higher efficiency of advertising conversion. So the relationship here is that short videos are available to users as merchandise, but the products here are free. Although free for users, someone has to pay for the development and operation of Internet companies. This "wool out of pigs" business model was first established by Yahoo! I've written an article before, "Reading the Top of the Wave," about this part, and interested partners can check it out.
In other words, it is advertisers who need to pay for the development and operation of Internet companies. Like users, advertisers have different audiences because of differences in their products. For example, an advertiser selling diet pills wants to push ads to people interested in diet pills, and a legendary game advertiser wants to push ads to people interested in legendary games, and so on. So the relationship here is that melon-eating users are "sold" to advertisers as merchandise, and the goods here are no longer free, and advertisers are required to pay for them.
At the end of the day, the relationship between users, advertisers, and voice-shaking platforms is that the platform sells video resources to users for free as merchandise, and users as goods paid to advertisers, that's all. For the platform to achieve higher revenue, it must improve the efficiency of advertising conversion, provided that users are attracted to increase the length of time to watch video, which involves video recommendations. Because.YoutubeThe deep learning recommendation system is based onEmbeddingdone, so the following leads outEmbedding。
02 One-hotCodingWord2vecto Item2vec
1. One-hotCoding.
Usually we use it in machine learningOne-hotCoding encodes discrete features. The little buddies are going to ask, what is it?One-hotCoding?
For example, we now have four words:"i","love","legend","game"。 The computer itself can't understand the meaning of these four words, but we now represent them in a code."i"The code is1000,"love"Coded into0100,"legend"The code is0010,"game"The code is0001。
Right.One-hotPopular understanding is how many words, how many bits. If so8words, we need length for8of the“01”Strings to represent words. Each word has its own order, then for each wordOne-hotThe time of encoding is placed at that location1Everything else is set0。
Now that we've entered the codes for these four words into the computer, the computer can understand what each code represents. This is the formOne-hotCoding. Pass.One-hotCoding makes it easy to represent these texts.
One-hotThere's a problem with coding, there are four words in the example above, and we need length4of the01string to represent. If so100Wwords, then we need length100Wof the01String to code? This is obviously inconvenient. So.One-hotThe biggest problem with coding is that the vectors are very sparse. Vectors, especially for extremely large commodity categories, can be extremely sparse.
Today is in the era of deep learning fire of artificial intelligence, One-hotThe sparse vector problem caused by coding is very detrimental to deep learning and engineering practice. The main reason is that the gradient drop algorithm is used in deep learning to train the model, and updating only a very small number of weights at a time when features are too sparse can cause the entire network to converge too slowly. In the case of limited samples, the model may not converge at all.
2. EmbeddingAppear.
Then came the showEmbeddingtechnology, especially in deep learningEmbeddingTechnology is so popular that it's even there"Everything is Embedding"said. Some little partners may be curious about what exactly isEmbedding?
The popular understanding is thatEmbeddingIs to use a low-dimensional space to represent an object, this object can be a word, a commodity, a video or a person and so on. We express an object through another space, and most importantly, we can reveal the potential relationship between objects, a bitSee the essence through the phenomenonmeaning.
In the human world, for example, we think there is a potential relationship between "The Chainsaw Horror" and "The Curse" because they are both horror films. But for the machine, I didn't know what the two things had to do with it, but after EmbeddingAfter the operation, the machine learned the potential relationship between the two, which can be said through the names of the two films(Surface.)See that they all belong to horror movies(Essence.)。 That's itEmbeddingthe magic of it.
Not only that,EmbeddingIt also has a mathematical relationship, such as existenceEmbedding in Sichuan - Embedding in Chengdu - Embedding in Guangdong - Embedding in Guangzhousuch a relationship.
3. Word2vecDetonated.EmbeddingTrend.
We use E in the field of natural language processingmbeddingTechnology for word coding, also known asWord Embedding。 really detonatedEmbeddingThe technology is2013year GoogleSuper-fireWord2VecTechnology.Word2VecTechnology maps words to vector space, representing text through a set of vectors.Word2VecThe technology is very good to solveOne-hotCoding causes problems with high latitude and sparse matrices.
The following image is of us passingWord2VecMap text to 3D stereospace:
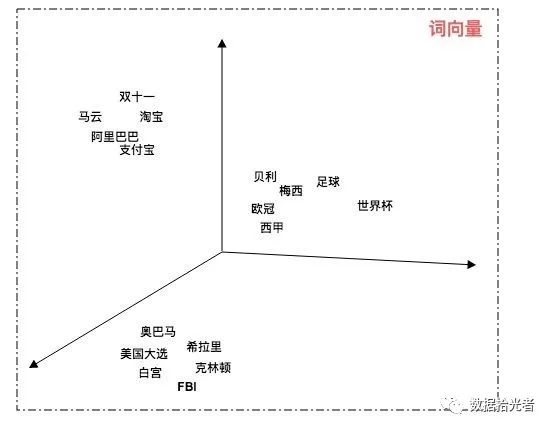
Figure.2 Word2VecMap to a 3D spatial display
Pass.Word2VecTechnology allows us to represent text in low-latitude space. We can also represent semantic similarity by calculating the distance in the word vector space. From the chart above we can see that football and the World Cup are relatively close, Obama and the U.S. election is closer, Jack Ma and Alibaba are closer and so on.
Word2vecThere are two model structures:CBOWAnd.Skip-gram。CBOWIt is through the context of the word to predict the current word, a very good understanding of one way is that we were a child in the English exam to fill in the blanks. Give you a passage, key a few words in the middle, and then let you predict the keyed words according to the context. And the other oneSkip-gramOn the contrary, words that predict context based on the current word are more abstract and do not give examples.CBOWAnd.Skip-gramThe structure looks like this:
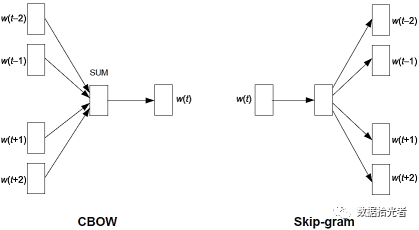
Figure.3 Word2VecTwo structures
4. From.Word2vecTo.Item2vec
Since.Word2vecDetonated.EmbeddingAfter that, soon EmbeddingRadiation from the natural language field to all areas of machine learning, including advertising, search, recommendation and so on. Take the short video in the recommended field, we recommend the next video to the user based on the short video sequence that the user is watching. We're building because of the sparseness of data, such as users, video, and so onDNNNeural networks need to be on the user beforeuserand videovideoTo make Embeddingoperation before feeding the model to train. About.Item2vecOne paper recommends:Item2Vec:Neural Item Embedding for Collaborative Filtering。
Essentially, Word2vecIt's just Item2vecOne of the applications to the field of natural language processing. The difference isWord2vecThere are sequential relationships, and the semantics that may be expressed by the same words because of the different orders are also quite different. AndItem2vecis abandoned in the sequenceitemspace relationship, without the concept of a time window. Take a user watching a short video for a period of timeABCDEFGAnd.EFGDCBAWe think it's the same, it's more about considerationitemthe probability of the condition between them. Below is paper Item2vecTarget function:
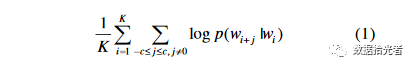
Figure.4 Item2vecThe target function
introducedItem2vecBelow we officially enter a net to playYoutubeDeep learning recommendation system, detailing how we use itEmbeddingTechnology to do user video recommendations.
03 YoutubeDeep learning recommendation system
1. YoutubeRecommended system background and challenges
The Chinese are rightYoutubeMay not be very familiar, here to take the jitter short video to analogy. Some of us may spend part of our day watching short videos for entertainment. For Jiyin, the longer a user watches a video, the higher the potential for commercial gain. There may be a reason for this. If we just watch the short video every day without any ad conversion, in fact, for the shaker will not really generate commercial revenue, the real revenue is to watch a video suddenly appeared that one or two ads. Only when these ads are clicked, downloaded, or even paid by the user will they increase commercial revenue. So small partners, here I sincerely suggest that we enjoy shaking sound to bring free happiness at the same time, but also do a little bit of their own thin force, dot advertising, download what, so as to really long flow of green water. Only the industry that really advertises can understand the hardships.
Jiyin short videos need to be recommended according to different user interests to recommend different types of short videos, in order to attract people to continue to watch. For example, if you give a user who likes to cook non-stop recommended games, then this user to see two will lose interest decisively do not look.
Figure.5 Youtubevideo recommendations on
In the field of recommended systems, especially for a large number of users such as Jiyin, we face the following challenges:
Super-large level of user and video scale, really face big data challenges;
Video and user behavior updates are very fast. In terms of video, there are a lot of video uploads every second, not only is there a hot issue, but it also needs to balance new video with stock video. On the user side, the user's interest change is also very fast, may like the game today, tomorrow like the other, so need to track the user's interest in real time;
There is a lot of noise in user feedback. On the one hand, the user's historical behavior is sparse and incomplete, on the other hand, the video data itself is unstructured, so the robustness of the model is very demanding.
2. The overall architecture of the algorithm
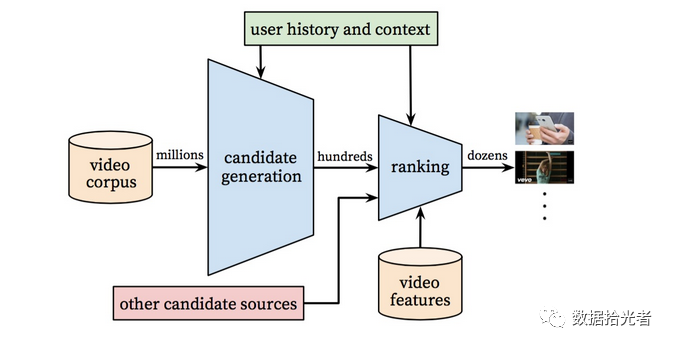
Figure.6 YoutubeAlgorithm.Overall.Architecture.
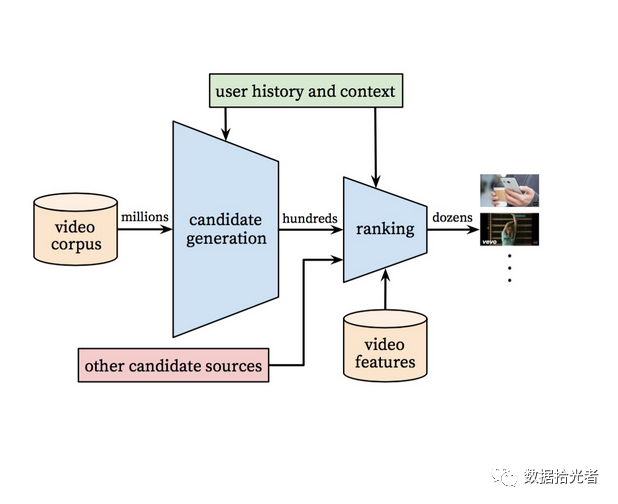
Overall,YoutubeThe deep learning recommendation system is divided into two segments, the first of which is Candidate Generation Model, ostensibly understanding is building a candidate model. Like.YoutubeSuch a large number of companies, with a large amount of video resources is also huge. For users, we may have millions of orders of magnitude of candidate video available for recommendation in the video resource pool. The main role of this model is to perform a screening operation from a million orders of magnitude video. After this round of initial screening, we selected a hundred orders of magnitude video from millions of levels of video that users might be interested in;Ranking, which can be understood as a fine-row operation. After this round of refining, we selected the dozens of orders of magnitude that the user is most likely to see from this hundred order of magnitude videos and sorted them, which will serve as a list of the videos the user will watch next. This is the overall framework of Youtube's deep learning recommendation system. Let's go into more detail about these two models.
3. Build a candidate modelCandidate Generation Model
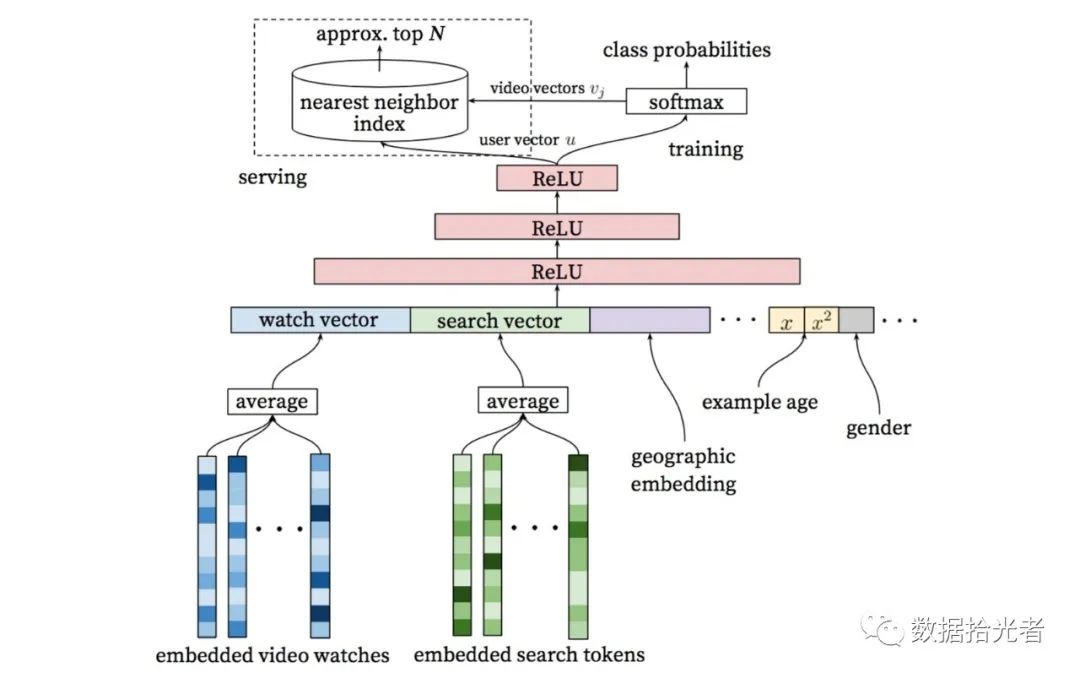
Figure.7 Build a candidate model
The build candidate model is shown in the figure above. Let's peel the wisp from the bottom up layer by layer. The bottom layer isEmbedded Video Watchesand Embedded Search Tokens, the author passedWord2vecMethod to the user to watch the video history and search term made EmbeddingOperation. After this wave of operation we can getWach Vectorand Search VectorTwo vectors, which act as feature inputs for the user to watch videos and search. In addition, we also have the characteristics of geographical location Geographic Embeddinggender-related characteristicsGenderWait a minute.
There is a special feature here calledExample Age。 The function of this feature is to characterize the user's preference for new video. Specific practices are, for example, user-in20200410afternoon20Point.18Clicking on a video produces a sample of the data. This sample corresponds when the later model is trainedExample Ageis equal to the moment when the model is trained minus20200410afternoon20Point.18divided this moment.
If the model training time distance sample is generated for longer than the time24hour, which is set to24。 This feature is set when the model is predicted online0, which is set here0It is also clear that the time to make predictions is at the last minute of model training. A practical phenomenon is that a good video just came out that will be the most easily clicked and forwarded by everyone crazy, after a period of time the heat will slowly come down to stabilize, that is, the video has a certain "time-called." The effect of adding this feature on the model is also confirmed in the paper:
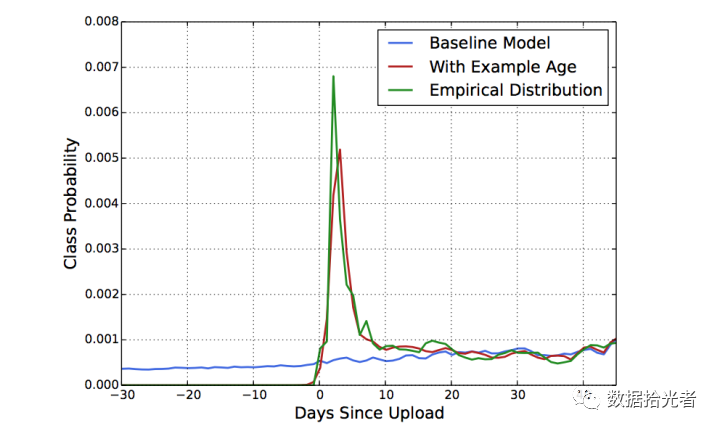
Figure.8 Example AgeThe effect of the feature
From the figure above we can find to joinExample AgeIt can make the model's predictions closer to the empirical distribution and more realistic.
This extends to the thinking in our current business:For the user to serve ads, the user for the freshness of the ads also have a certain preference.The same ads back and forth to the user exposure, advertising conversion effect should not be very good. Judging from whether the user likes or doesn't like an ad, if you like it before, you shouldn't order it again. Here is a life experience is that even If Zhou Xingchi's film people will not look back and forth in a short period of time, let alone advertising; This may be helpful for business practices.
After we get these different features, we stitch them together, and we're done with the feature preparation. Here are the three layers that feed these features to usReluNeural networks.
After three floorsReluNeural networks after we got itUser Vector。User VectorOn the one hand it will be used for model online services, on the other hand it will be used through oneSoftmax层,Softmaxthe probability that the current user might be watching a candidate million-level video, here in factit becomes a multi-classification problem。
Users may now watch this million-level video, each with a probability that the probability values add up1。 There's an engineering problem here, because there are millions of levels of video candidates, so it's equivalent to a million orders of magnitude multi-category, which can have a big impact on the effectiveness and speed of the model. So.YoutubeHow do engineers do it? The paper says it was carried outNegative sampling(Negative Sampling)and useImportance Weightingmethod to calibrate the sampling.
Here's an example of how negative sampling is done. Like we have now100Wcandidate video, in fact, there is100Wclass. Now there's a sample label that'sclass_3, because model training uses Softmaxfunction, so the model updates the parameters as much as possibleclass_3of theSoftmax valueBias.1Other.99W9999The S of the classOftmax valueThe output is biased0。 When we take negative sampling, if you set the number of negative samples to be9999, that's the equivalent of shielding99Wcategory, so that each update to the model makes the current category correspondSoftmaxClose.1Other.9999categoriesSoftmaxBias.0, "change" a million categories into ten thousand。 These engineering tumultuous operations above enable the generation of candidate models to respond to model training and model effects even in the face of millions of orders of magnitude classification.
After SoftmaxThen we got the video vectorVideo Vector。 Here's another engineering problem, why?Use the nearest neighbor search algorithm to select a hundred levels of video? Here is the result of a trade-off between engineering and scholarship. If you use the trained model directly to predict candidate sets for millions of levels, the time overhead of the model is too high. A good choice is that we get it separately through the modelUser Embeddingand VideoEmbeddingAfter that, the nearest neighbor search method can greatly improve efficiency. Industry is generally generallyUser Embeddingand Video EmbeddingStored toRedisThis type of memory database.
Here's the little buddy curious about thisUser EmbeddingAnd.Video EmbeddingHow specific, let's talk about it in detail. Here's a detailed example:
About.User EmbeddingWhen our model training is complete, if we use it100Dimensions to represent User Embdding, then the dimension of the output of the last layer of our hidden layer is100X1the output of the hidden layer asSoftmaxThe input of the layer, that is, SoftmaxThe input of the layer is100X1V, and this one100X1Vi isUser Embedding。 Because the user's behavior is constantly updated, the user's behavior is constantly updatedUser EmbeddingIt is also constantly updated and requires real-time computing. It is best to do this in a real-world project with sufficient resources, such as machinesUser EmbeddingAnd.Video Embedding high frequencyupdates, which allow users to access the input layer with the latest viewing and search behavior to get the most up-to-date users who respondUser Embedding。DNNThe input is the video that the user was watching and searching for(Relatively large changes)and user portraits(relatively stable)Feature combination, each into three layersReluGet one100X1dimensional vector, which is real-timeUser Embedding;
About.Video EmbddingAnd if we candidate the video has200Wthen we SoftmaxThe output layer of is200WX1Because.Softmaxis the probability value that each video will be viewed by the user the next time. So SoftmaxThe weight matrix of the layer isW(100X200W), it's trans-positionedW(200WX100)。 Because there is200Wvideo, so yes200WLine, each video is100X1and get the V for each videoideo Embedding。
Get it hereUser Embeddingand Video EmbeddingAfter that, when we're going to calculateuser_iWatch.video_jprobability, you can pass two100The dimensional vector is made of internal product.
There are also several engineering aspects involved in cattle-forced operations:
Each user generates a fixed number of training samples。 In a real-world scenario, there will always be some more active users, and these highly active users willlosshave an excessive impact. In order to eliminate this part of the impact, we use a fixed sample for each user, treating each user equally;
YoutubeCompletely.Time series information for users viewing videos is discarded, treat the videos that users have watched for a while equally. It's actually easy to understand here. When we recommend too many results from a recently viewed or searched video, it can affect the user diversity experience. For example, even if a user likes the king's glorious video again, you constantly recommend this type of video, the user will certainly be aesthetically fatigued. Because usually the user will have more than one interest, so we need to do in the user's multiple interests loop, so that the user is interested but not tired;
To the videoEmbeddingThe operation of the putA large number of long-tailed videos are used directly0Vectors instead。 This is also based on classic engineering and algorithms of a trade-off, a large number of long-tailed video truncation, the main purpose is to save valuable memory resources for online services;
YoutubeEngineer.Select the last video the user watched as a test set, the main reason is to prevent the introduction of future information, resulting in data crossing phenomenon that does not match the actual situation;
Diversity of data sources。 The model uses not only video viewing history, but also user search. Rich data sources can multi-dimensional portray of the user's interest, which is also our actual work to label the user is very important;
About the candidate modelDNN network structure design, the most cost-effective solution is 1024Relu-512Relu-256Relu。
On the business side, it is also important to noteThe determination of model optimization objectives。YoutubeThe recommended system targets user viewing time for model optimization, which is the result of both model and business analysis. The model needs to reflect the real interest of the user, and choosing viewing time may be more effective than click-through or playback rates. Sometimes the user although clicked on the video, but may have watched two seconds feel no fun, when the click-through rate as an evaluation indicator, this sample is the case, but the reality is that the user may not be interested in this video. But if you choose to watch time can further reflect the user's interest, can not be interested in the premise of insisting on watching the video is very few. So the reference here for our machine learning engineers is to develop the model to go deep into the business, after all, the model is ultimately to serve the business. Identify the goal of model optimization to be half successful.
At this point, we've finished the instructions for generating candidate models, and let's move on to the second refined model.
4. Refined model Ranking
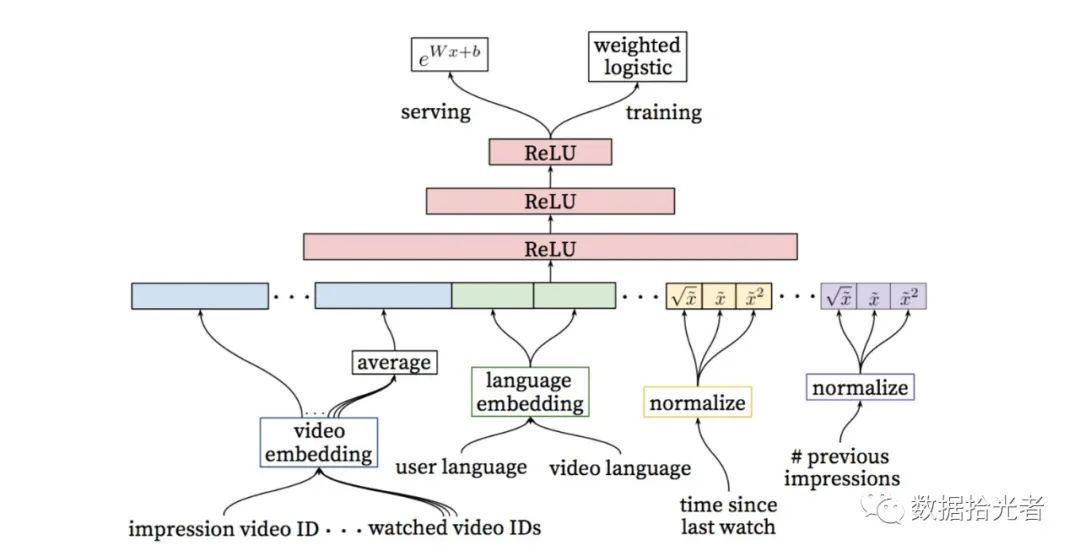
Figure.9 Fine-row model
As shown in the figure above, you can see that the refining model is very similar to the model that generates candidates. The difference is between feature engineering and the top part. In fact, the paper also has the explanation, the refined rehearsal stageDNNThe purpose of the model is to add more video description features, user characteristics, and characteristics of the relationship between the user and the video, so as to really achieve the goal of re-lining the candidate video. We also dissect from the bottom up. The first is the bottom-level feature engineering, which is described from left to right:
Video Embedding: This is mainly includedImpression Video IDand Watched Video IDS。 whichImpression Video IDis the video you are currently calculatingEmbedding,Watched Video IDSIt was the last user to watchNvideoEmbeddingAverage;
Language Embedding: This mainly includes User Languageand Video Language。 Where User Languageis the E of the user's languagembedding,Video LanguageIt's video languageEmbedding;
Time Since Last Watch: This is the last time a user saw the same typeChannelThe time interval of the video;
#Previous Impressions: This is the number of exposures recorded to the current user for the current video.
whichTime Since Last WatchAnd.#Previous ImpressionThese two characteristics pay good attention to the relationship between the user and the video.Time Since Last WatchPrimarily used to focus on the interval between the time a user watches the same type of video. This is one from the point of view of user interestAttentionBehavior. If the user has only seen the "King Glory" type of video, then the user is interested in this type of video, so the later viewing list to add this type of video users should also like to watch. This involves the part where the recommendation system needs to label the user. The ultimate goal of this feature is for users to watch certain types of videos and be interested in them. Previously shared an article through the user's mobile phone behavior to label the user's first unified interest modeling process, interested small partners can look at.
#Previous ImpressionFeatures are designed to allow the model to take care to avoid repeated exposure of a video to the user, resulting in invalid exposure. Feel that this feature interacts with the Time Since Last Watch above. The above feature is to let the user mark, understand that the user is interested in a certain type of video. This feature tells the model to be moderate. Crazy recommendations that don't show users interested in a video. These two features and the previously mentioned we want to let users watch the video both interested and not tired. It's still hard.
It is worth noting that both of the above features have been carried outNormalization operations。 Not only that, but also the normalized featuresOpen and squared after treatment when different characteristics are fed to the model。 This is a simple and effective engineering experience that introduces the nonlinearity of features through open and square operations. Judging from the effect of the paper feedback, this operation enhances the evaluation index of the model offline.
Here's the same thing, stitching these features together and feeding them to the model. It's followed by three floorsReluNeural networks. The weighted logistic regression function Weighted Logistics Regression is then used as the output layer. The main reason for using the logical function with weights here is that the model uses the video expected viewing time as an optimization target, which can be used as the weight of the positive sample and passed when providing online servicese(Wx+b)Make predictions to get an approximate of the expected viewing time.
Here, we have finished the explanation of the fine-row model.
Summarize.
This is the main analysisYoutubeDeep learning recommendation system, drawing on model frameworks and excellent solutions in engineering to apply to real-world projects. First of all, we talk about the relationship between users, advertisers and video platforms such as Jiyin: that is, the platform to sell video resources as a commodity free of charge to users, while the user as a commodity paid to sell to advertisers, that's all. For the platform to achieve higher revenue, it must improve the efficiency of advertising conversion, provided that users are attracted to increase the length of time to watch video, which involves video recommendations. Because.YoutubeThe deep learning recommendation system is based onEmbeddingdo, so the second part is speakingEmbeddingFrom the appearance to the fire. The last net was doneYoutubeDeep learning recommendation system. The system is mainly divided into two segments, the first paragraph is to generate a candidate model, the main role is to the user may be interested in the video resources from a million levels of initial screening to a hundred levels, the second paragraph is a refined model, the main role of the user may be interested in video from a hundred levels to dozens of levels, and then sorted according to the degree of interest to form a user watch list. The third part is also the focus of this article.
Resources.
1. 《Item2Vec: Neural Item Embedding forCollaborative Filtering》
2. 《Deep Neural Networks for YouTubeRecommendations》
Note: This black bold part is a practical experience that is useful for practical projects, small partners can focus on.
The latest and most complete article please pay attention to my WeChat public number: data picker.

Go to "Discovery" - "Take a look" browse "Friends are watching"