Author . . Liang Tang Source . .TechFlow(ID:techflow2019)Header figure . . CSDN is downloaded from Oriental IC
Today we're dissecting a classic paper: Practial Lessons from Predicting Clicks on Ads at Facebook. As can be seen from the name of this paper, the author of this paper is Facebook's advertising team。 This is a combination of GBDT and LR model application in ad click-through rate prediction, although it has been several years, but the method is still not completely outdated, there are still some small companies still in use.
This paper is very, very classic, so to speakRecommended, must-read articles in the advertising fieldIt's not too common sense in the industry. The quality of this article is very high, the content is also relatively basic, very suitable as everyone's entry paper.
This article is a little long, it is recommended to look first.
Brief introduction.
The beginning of the paper gives a brief overview of the status of advertising in the Internet industry at the time and the size of Facebook at the time, when Facebook had 750 million daily active users and more than one million active advertisers, so the importance of choosing the right and effective ads for Facebook to serve to its users is enormous. On top of this, Facebook's innovative approach to combining GBDT with a logical regression model yields more than 3% in real-world data scenarios.
In 2007, Google and Yahoo proposed an online bidding ad-fee mechanism, but Facebook and search engine scenarios are different, in which users have a clear search intent. The engine filters ads based on the user's search intent, so the candidate's ad set won't be very large. But Facebook doesn't have such a strong intention message, so Facebook has a much larger number of adstherefore, the pressure and requirements on the system are also higher.
But this article doesn't talk about system-related content.Focus only on the last part of the sort model。 It's not said in the paper, but we can see that ads in search engines like Google and Yahoo are search ads, and those ads on Facebook are recommended ads. The biggest difference between the latter and the former is that the logic of recall ads is different, somewhat similar to the difference between a referral system and a search system.
At the heart of this is the user's intent, and while the user has no strong intentions when they log on to Facebook, we can extract some weak intentions based on the user's previous browsing behavior and habits. For example, the user stays on which kind of goods for the longest time, the most clicks on what kind of content, and similar to the collaborative filtering of the user's behavior abstracted into vectors. In fact, there is a lot of content, but also very valuable, it can be seen that Facebook in writing papers are left a hand.
Specific practices
After saying the nonsense we look at the specific practice, the specific practice many students may have heard that is the GBDT-LR practice. It seems like a word is over, but there are a lot of details. For example, why use GBDT and why does GBDT work? What are the mechanisms in force here? What is written in the paper is only superficial, and the thinking and analysis of these details is the key. Because the practice in paper is not universal, but the implications are often universal.
First of all, model evaluation, paper provides two new methods of evaluating models. One is Normalized EntropyThe other is Calibration。 Let's start with the model evaluation.
1、Normalized Entropy
This indicator is quite commonly used in real-world scenarios and is often seen in the code and paper of various gods. Direct translation is the meaning of normalized entropy, the meaning has changed a little, can be understoodCross entropy after normalization。 It is calculated by the ratio of the cross entropy average of the sample to the cross entropy of the background CTR.
Background CTR refers to the experienced CTR that trains sample sets and can be understood as an average click-through rate. But here's to note that it's not the ratio of positive and negative samples. Because we do it before we train the modelSampling., for example, if sampled on a plus-minus sample ratio of 1:3, the background CTR here should be set as a ratio before sampling. Let's assume that the ratio is p, so we can write the formula for NE:
Over here.The value of is, that is, click is 1, no click is -1. This is the formula in the paper, in practice, we generally write click as 1, impression (no click) as 0.
2、Calibration
Calibration translates to mean calibration scales, but here I think it should be understood as a deviation from the baseline. This indicator isThe ratio of the average CTR to the background CTR predicted by the model, the closer this ratio is to 1, the smaller the baseline deviation of our model and the closer it is to the real situation.This formula can be written as:
3、AUC
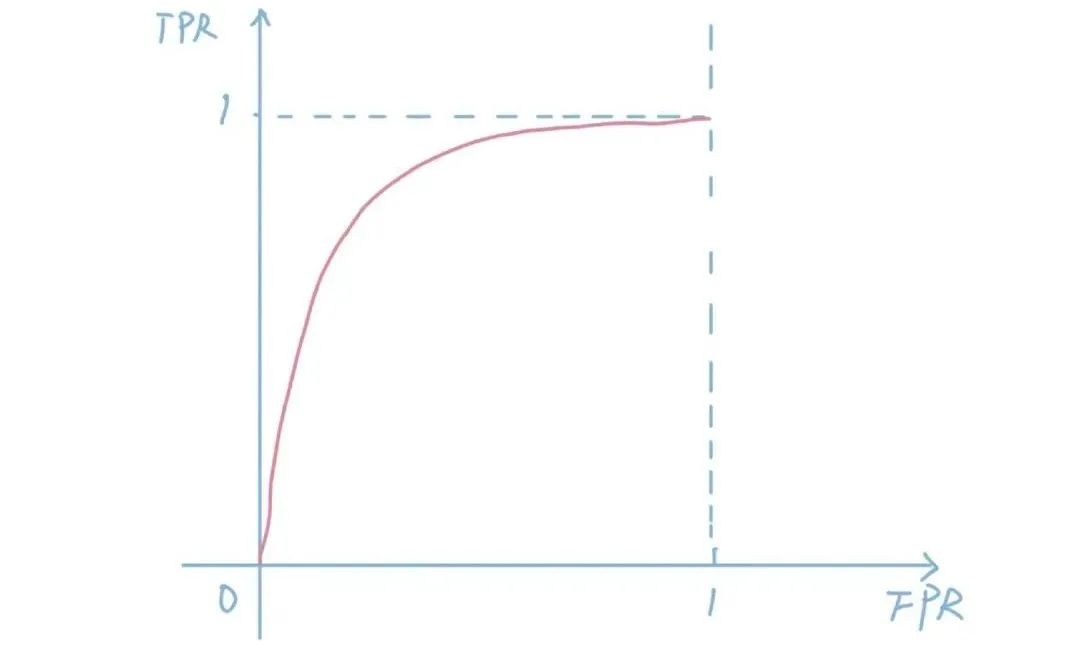
AUC is a regular and we areThe most commonly used indicator in industryand hardly one of them. AUC, as we described in previous articles, represents the Aera-Under-ROC, which is the area around the ROC curve. The ROC curve is a curve consisting of TPR (true postive rate) and FPR (false positive rate). The larger the curve area, the stronger the model's ability to distinguish between positive and negative samples, and in the CTR sorting scenario, whether the model can predict accuracy is not the most important, and the ability to filter out positive samples is the most important, which is why AUC is so important.But AUC is not without drawbacks, as listed in Paper. For example, if we calibrate all the CTRs predicted by the model x2 and then multiply all the predictions by 0.5, the AUC will still not change. But if we look at NE, we see that NE has gone up.
4, the combination of models
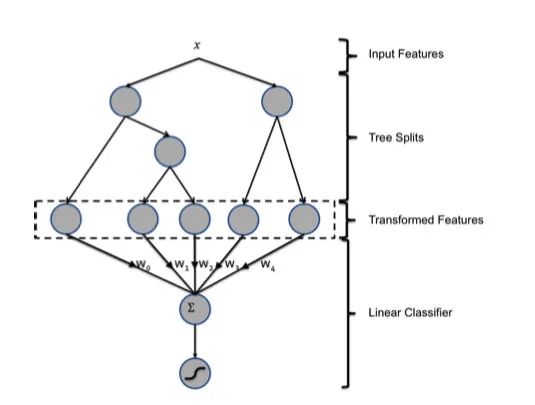
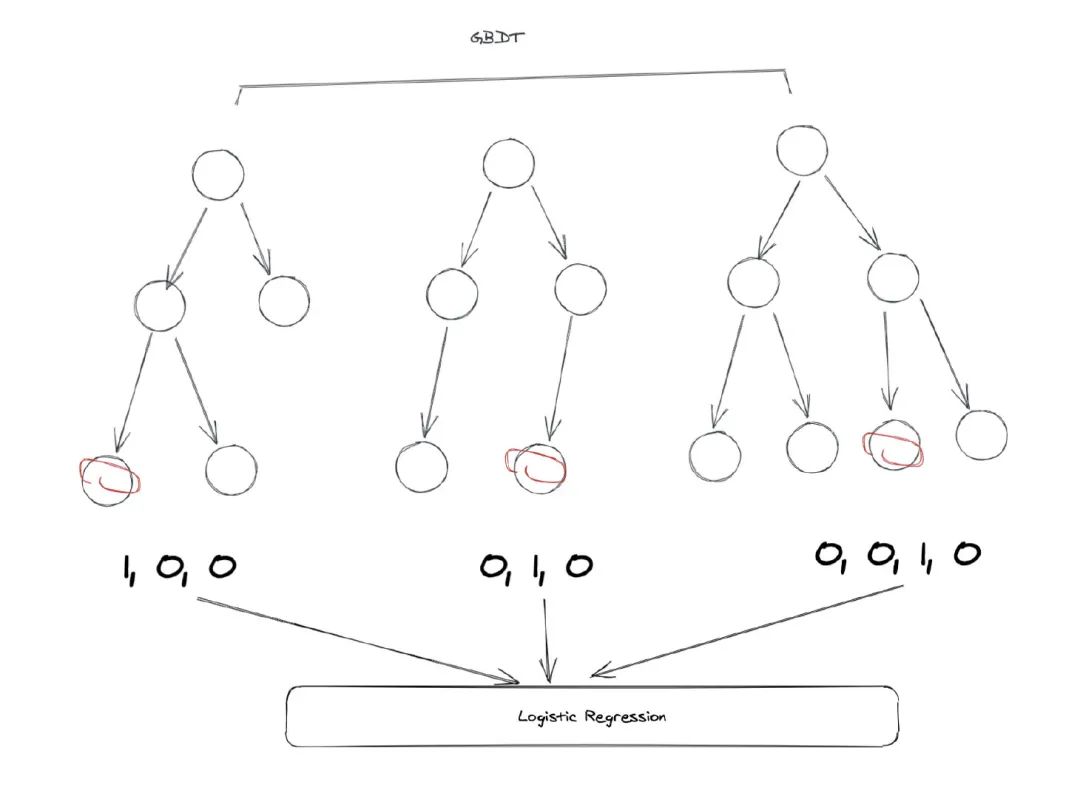
It's finally time to play, and although there's a lot of other things in this paper, we all know that GBDT-LR is the point. GBDT and LR are both familiar to us, but how do they combine?In fact, the problem itself is wrong, so-called GBDT-LR is not a combination of two models, but a transformation of characteristics. That is to say, we need to think from a characteristic point of view rather than from a model.Paper first talks about two common ways to handle features, the first of which is called bin, which is called binBucketmeaning. Income, for example, is a continuity trait. If we put it in the model, what the model learns is that it has a weight, which means it works linearly. In a real-world scenario, however, it may not be linear at all. For example, the brands that rich people like may be completely different from the poor, and we hope that models will learn nonlinear effects. A better approach is to do soArtificially bucket this featureFor example, according to income divided into annual income of less than 30,000, 30,000 to 100,000, 100,000 to 500,000, and more than 500,000. Which bucket falls into, which bucket is marked with a value of 1, otherwise it is marked with 0.The second method is calledThe combination of featuresThis is also well understood, such as whether gender is a category and whether high-income groups are a category. Then we can arrange the combination, you can get men, low income, male, high income, women, low income and high income four categories. If it is a continuity feature, it can be discrete using a data structure such as kd-tree. We can get more features by crossing category features, but these features are not always useful, some may not be useful, and some may be useful but the data is sparse. So while this can produce a lot of features, howeverManual filtering is required, and many are invalid。Because the amount of manual filtering of features is too much and the benefits are not high, engineers began to think about the question: Is there a way to automatically filter features? Now we all know that neural networks can be used for automatic feature cross-cutting and screening, but neural networks did not rise at that time, so they can only be done manually. To solve this problem, engineers at the time thought of GBDT.That's why there's GBDT-LR, let's look at this picture:Let's take a brief look back at the GBDT model, first of all GBDT is a forest model of multiple trees。 For each sample, it falls on one of the leaf nodes of each sub-tree at the time of prediction. So we can use GBDT to map features, let's look at an example:In the example above, there are three sub-trees in GBDT, the first of which has three leaf nodes. Our sample falls to the first one, so the first sub-tree corresponds to the one-hot result of 1, 0, 0, the second sub-tree also has 3 nodes, the sample falls into the second node, so the result of one-hot is 0, 1, 0, the result of the third sub-tree can be obtained by the same reason.So we end up merging the vectors of these trees and we get a new vector: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .This vector is the input to our LR model。Let's analyze the details, let's be clear first.GBDT is only used for feature conversion and processing, and its predictions are not important。 By using GBDT, we did both of the two operations we just mentioned.The continuous feature is transformed into a discrete feature, and the crossover of the feature is also completed automatically.Because for each sub-tree, it is essentially a decision tree implemented by the CART algorithm, that is, the link from the root to the leaf node represents a potential rule. So we can approximate the use of GBDT instead of manual rule extraction and feature processing.
Results.
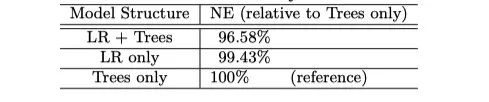
Finally, let's look at the results, the original paper carried out three sets of experiments, respectively, only LR, only GBDT and GBDT-LR to compare. The measure is the respective NE, and with NE's largest Trees-only as a reference, you can see that the NE in the GBDT-LR group decreased by 3.4%.We post the results in the paper:However, this result is quite clever, because the contrast is NE, which means that cross-entropy has decreased. But. The AUC situation is not known, and it is not said in paper。 And this decline is based on NE's largest results, with a slightly exaggerated feeling. Of course, this is also a common means of paper, we have a number in mind.
The real-time nature of the data
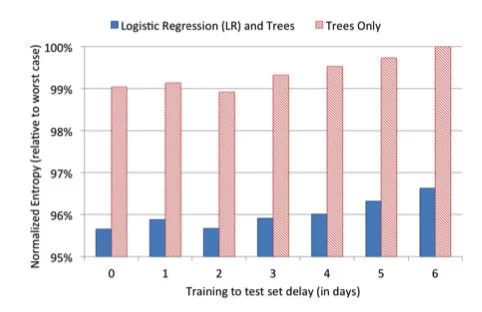
In addition to innovations in models and features, this paper explores the role of data errativeness.To verify the relationship between data freshness and model performance, paper selects a piece of data to train the two models, trees-only and GBDT-LR, and then uses the two models to predict the data for the next 1 to 6 days, respectively, to chart the overall situation:In this diagram, the horizontal axis is the number of days to predict the distance from the training data, and the vertical axis is the NE of the model. The lower the NE, the better the effect of the model, and from the figure above we can see that the difference between the results of the sixth day and the NE on the 0th day is about 1%. That meansSimply maintaining the freshness of the data allows us to get a 1% increase.That's why companies do online-learning.
online learning
In the next part, paper also introduces us to some of the details of online learning. Some of them are out of date, or not universal, and I've picked a few typical and representative lists.
1, the time window
In our process of collecting training data, clicks are more explicit because clicks have a specific behavior, but impression (exposure) is not. Because the user did not click this is not an act, so we can not determine whether the user does not want to point or wait a little longer. It is more common practice to maintain a timed window,Set a time, if the user sees that the ad did not click within the specified time, then this is considered a non-click event.But it's easy to see that doing so is problematic because the user may be unresponsive, or it may not have responded for a time and not clicked. It may be that time has passed and the user clicked on the situation. In this case, the impression has been recorded as a negative sample, and the positive sample generated by clicking cannot find the corresponding impression. We can calculate a ratio of how many clicks can be found in impression, which is called click coverage, click coverage.Is that the longer the window, the better? Not really, becauseToo long a window may result in putting some that are not clicks that are considered clicks。 For example, for example, an item, the user is not satisfied the first time they browse, so there is no point. After a while, when the user came back to see it, he changed his mind and clicked. Then it is reasonable to think of the first point-without behavior as a negative sample and the second behavior as a positive sample. If our time window is set very long, it will be considered a click sample. So the time window in the end should be set for much longer, this is a parameter that needs to be adjusted, can not pat the head to decide.
2, architecture
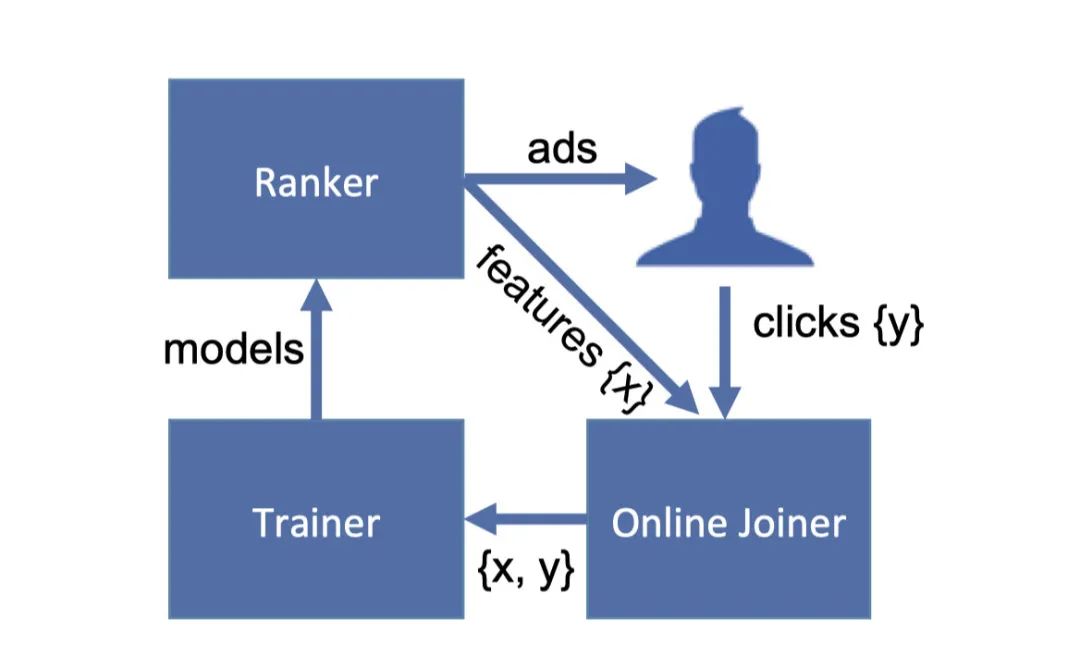
Streaming is a commonly used method of data processing in the industry, called streaming. It can simply be understood as a queue, that is, queue. But when click occurs we need to find the corresponding impression sample and change it to a positive sample, so we also need to look for the functionality. That means we also need a hashmap to record nodes in the queue.When we collect enough data, or sample data for a specified amount of time, we use the data in the window to train the model. When the model is trained, it is pushed into the sorting system, and the model files that need to be called for sorting are updated in real time, so as to achieve the goal of online real-time training. Let's look at its architecture diagram:Ranker is a sorting system that sorts candidate ads and displays them to users, and pushes the feature data for those ads to the online joiner, which isFeature processing system。 When a user clicks on an ad, the clicked data is also passed in to Joiner. Joiner associates the user's click data with the data transferred by Ranker, which then transmits the data to the Trainer system for model training.There is also a detail here, that is, how do we relate in joiner? Because a user may have data to watch an ad more than once, the same ad may refresh to view multiple times. So it's not possible to associate directly with a user's id or an ad's id, and we need a time-related id. This id is called requestid,Each time a user refreshes a page, the requestid refreshes, so that we can guarantee that even if the user refreshes the page, we can correctly associate the data.
Feature analysis
Finally, some analysis of the features is attached to the paper. Although we don't know exactly what characteristics they all use, the content of these analyses is still useful to us.
1, behavior characteristics or context features
In the SCENARIO scenario, the features can be divided into two main types, one isThe context featureOne isThe characteristics of the user's historical behavior。 The so-called contextual feature is actually a big concept. Information about the current and scene, such as the information about the ad being displayed, the user's own information, and the time at that time, the content on the page, the user's location, and so on, can be considered contextual information. Historical behavior characteristics are also well understood, i.e. behavior that users have previously generated within the platform.Paper focuses on the importance of user behavior characteristics, in which the features are reversed by importance and then calculated as a percentage of the user's historical behavior characteristics among the important features of topK. In the LR model, the importance of the feature is equivalent to the weight of the corresponding position, and the result is as follows:As we can see from the results of the figure above,The historical behavior characteristics of the user occupy a very large weight in the whole。 Only two of the top20 features are contextual features. This is also in line with our understanding that the quality of the content we deliver is far less important than what users like. And the data that has generated behavior in the user's history is a very good reflection of the user's preferences.
2, the importance of analysis
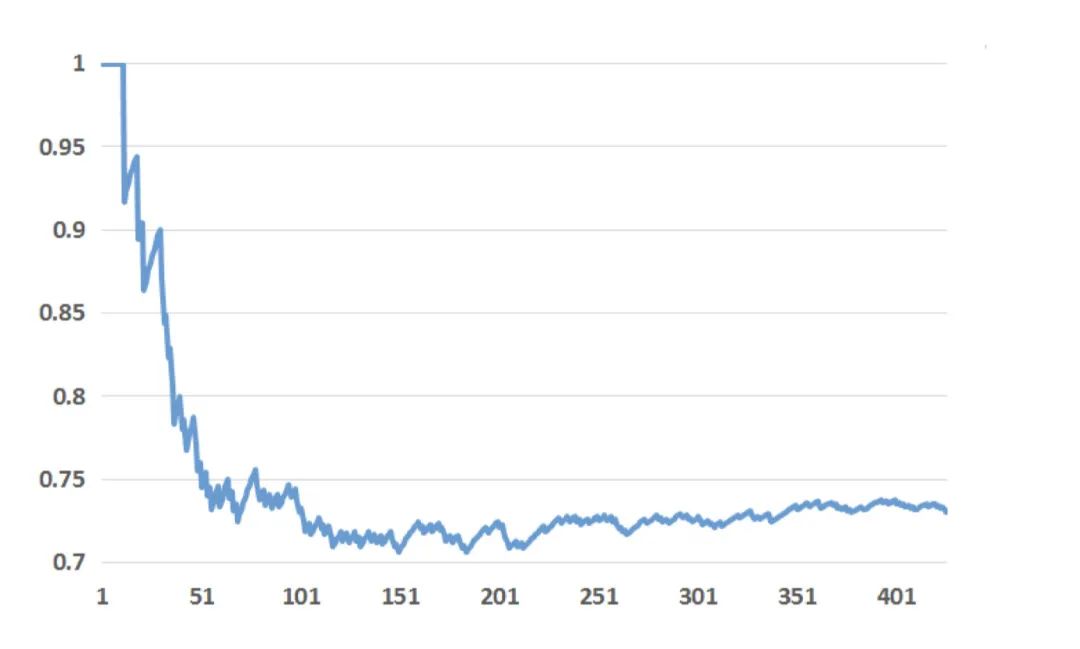
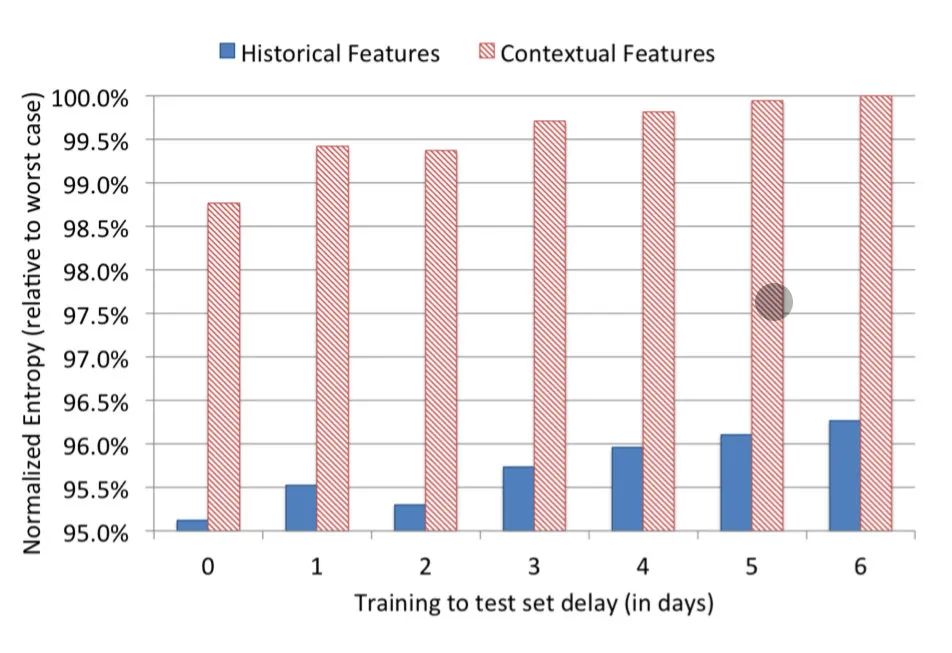
In addition to analyzing the importance of features, paper experiments with predicting only one type of feature to compare the performance of the model. The results of the experiment are as follows:The red bar in the image above shows the training results that use only context features, and dark blue is the training results that use user behavior features only. From this result we can clearly see thatModel performance trained with behavioral features is at least 3.5 points better than using context featuresThat's already a very big gap. So we can also conclude that user behavior characteristics are more useful than contextual characteristics.In addition, the effects of negative down sampling (negative sampling) and subsampling (secondary sampling) on model performance are discussed in paper. whichSecondary sampling proves that the amount of training data is positively compared with the overall effect of the model, that is, the larger the amount of training data, the better the effect of the model。 Negative sampling is also helpful for improving the effectiveness of the model, which is the usual method in current advertising and recommendation scenarios.




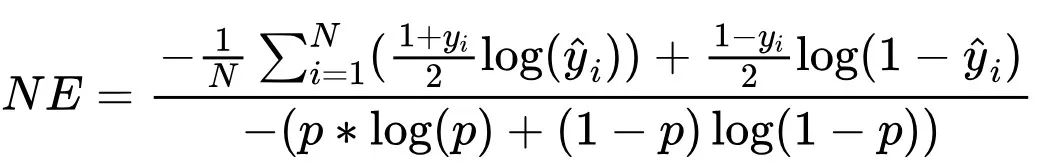









Go to "Discovery" - "Take a look" browse "Friends are watching"