The artificial intelligence principle of Facebook's ad recommendation algorithm

Cecilia Cecilia
Programs and Digital Marketer
He lives in Montreal, Canada

As a digital marketer, Cecilia has always been interested in the workings behind Facebook ads.
You can find a lot of articles about Facebook's advertising bidding algorithms online. But because it's not publicly available, there's little discussion about algorithms that recommend audiences in ad serving.
Cecilia, who had previously worked on machine learning, and some small thoughts and research on AdTech, decided to do her own food and clothing and write the story behind the Facebook ad herself. 😄
This is a technical analysis post about Facebook's advertising (recommended audience) algorithm.
The aim is to explore the role of machine learning and artificial intelligence in algorithms and to demysties the "black box" mechanism.
Cecilia tries to be as colloquial as possible, and only picks the parts that are more useful to advertising pitchers. Too detailed too deep content, let's leave it to academia.
01
Social networking and artificial intelligence
First, Cecilia felt the need to simply distinguish between the concepts of "artificial intelligence" and "machine learning".
Artificial intelligence has been on fire lately, and it's actually a broader term for all human behavior that can be imitated by computers and performed manually instead of humans.
Machine learning is the practice and application of artificial intelligence, which trains algorithms and data models through big data to make more accurate predictions and judgments about new (unknown) data and instructions.
Going further down, it's deep learning and things like that, and as an advertising pitcher you don't need to know anything academic or professional.
Cecilia's main noun in this article is "machine learning," but let's be aware that artificial intelligence and machine learning are in some cases the same thing.
The concept of artificial intelligence was actually put forward very early, do you remember the classic movie Hacking Empire? The film talks about the struggle between humans and machines with superior IQs.
But why have fires only started in recent years?
Because artificial intelligence relies on data-driven, earlier computers had no way to process large amounts of data at high speed.
Until the bottleneck of the hardware industry is broken, mass data parallel processing CPU and even more powerful GPUs, AI can finally get rid of the shackles, enjoy all available information, the development of thousands of miles a day.
So it's easy to say that without data, there's no artificial intelligence.
So, where does the data come from?
In addition to specialized research data collection, hundreds of millions of users spontaneously generate data (UGC) every day for social networks like Facebook: photos, movies, voice, text, social interactions, and more.
In addition, Facebook can track everything you do on the Internet through cookies in your browser.
Like which websites have you visited? What have you searched for? What purchases have you had?
There is a passage on Facebook's official website that:
“ We use cookies to help us show ads and to make recommendations for businesses and other organizations to people who may be interested in the products, services or causes they promote.”
So Facebook is mainly through tracking browserscookieto collect the user's data,Then predict the user's preferences and behavior, and choose the most suitable advertisement to present in front of the user。
Facebook, meanwhile, uses cookies to determine how it controls the delivery of ads and evaluates the quality of them.
For example, make sure that the ad appears no more than X times on the same user's timeline. Another example is whether the user interacts with the ad (click, message, like, purchase... and so on).
As a tip-taker in the Internet age and a social networking head, Facebook has the world's most valuable data: more than 2 billion active users around the world.
But wherever you walk, you leave a mark.
Everything you do on the Internet is converted into data that your computer can read and use.
02
The application of machine learning algorithms on ad audience recommendations
The Facebook ad algorithm is a predictive algorithm.
Simply put, machine learning algorithms use feedback (historical data) from "learning" ad delivery to predict the effectiveness of new ad delivery.
There are two categories of machine learning algorithms:Regression AlgorithmsAnd.Classification algorithm (classification)。
The result of the regression algorithm is someConsecutive values, for example, a straight line in a binary secondary equation, any horizontal coordinate of the X value, you can find a corresponding Y value.
The output of the classification algorithm is not continuous, but more like one paragraph after anotherInterval.。
For example🌰 when you ask, "Will this user click to buy my product when they see the ad?"
Through analysis,Classification algorithmI'll tell you, yes or No.
But.Regression algorithmWill tell you "only 68.59 percent of the probability will buy, there is a 31.41 percent chance of not buying."
In fact, the two algorithms are not completely incompatible with each other.
For example, you specify the interval in the output layer of the regression algorithm, "no below 60%" and "Output value of no less than 60% is Yes", so onThe regression algorithm is transformed into a classification algorithm。
Regardless of the algorithm used, the core of machine learning in the field of ad delivery is to predict TA's behavior by analyzing the characteristics of the audience.
Each attribute of the user is an "argument X", and the output value of the model, which is the "factor variable Y".
In a regression model, a fitted equation can be written as:
Y = a*X1 + b*X2 - c*X3 +d*X4。。。
Where X1 / X2 / X3 / X4... What it might mean is:
- Gender,
- Age,
- Address,
- Is it Engaged shopper,
- Love of fashion,
- Like puppies,
- There's a newborn baby at home,
- Favorite colors,
- The type of music you like...
And a / b / - c / d... is a number of constant parameters that affect each argumentWeight.can also be understood as,The degree of influence on the factor variable Y。
The variable Y represents the target of your ad.
When you choose to buy, Y may represent whether the user will convert the purchase behavior. When you select a target, Video View, Y represents whether the person the ad was pushing will be patient enough to watch your ad.
Because Facebook's advertising algorithm is still private to the outside world, it's a black box.So both algorithms are actually possible, and may even be a combination of the two algorithms.
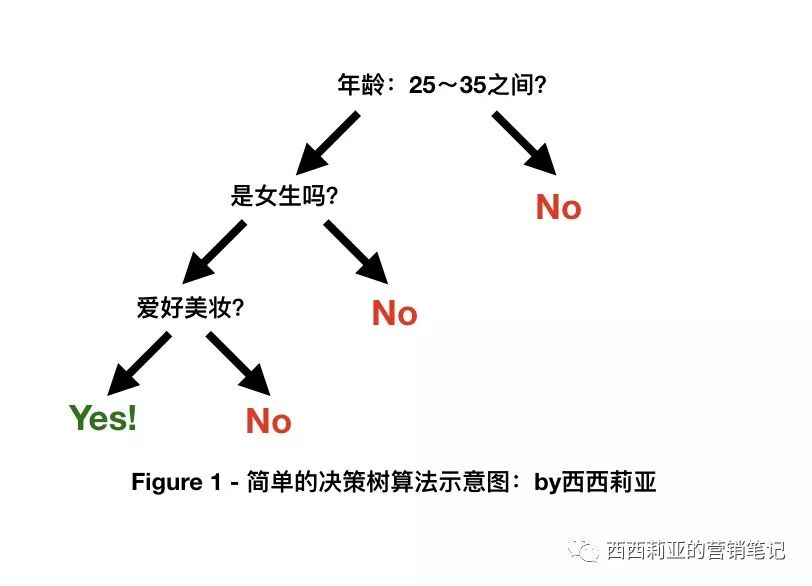
The simplest of the classification algorithms is"Decision tree"。
The decision tree is one of the most intuitive machine learning algorithms I think. The simplest decision tree is the "binary decision tree", where there are only two answers to each question: Yes or No.
For example, through training, Facebook ads algorithms found that people between the ages of 25 and 35 with a "female" gender and a love of "beauty and fashion" were the most likely to convert your ads.
Then, for every new "potential audience," Facebook's advertising algorithm asks:
“
- Is this person between 25 and 35 years old? No - PASS. Yes - go to the next question.
- Is this man a woman? No - PASS. Yes - move on to the next question.
- Does this person have a hobby related to "beauty fashion?" No - PASS. Yes - good! It's you! Beauty, there's an ad here, would you like to know something?
”
Next, soul painter Cecilia explains these algorithms with a few straight (super) (ugly) diagrams:
The regression algorithm is a little more complex.
The simplest and most basic algorithm is linear regression.
Suppose we have only one argument, X, which indicates the age of the user.
The variable Y is the target of our ad serving (Objective), for example, the probability of "buying" (probability).
This model is simple and crude, determining TA's buying behavior by the age of a user.
Based on the experience of advertising, we get someDiscrete pointsEach point can be described as (age, whether it will be purchased), such as (25, Yes), (65, No), (30, Yes).
The resulting curve may look like the following image:
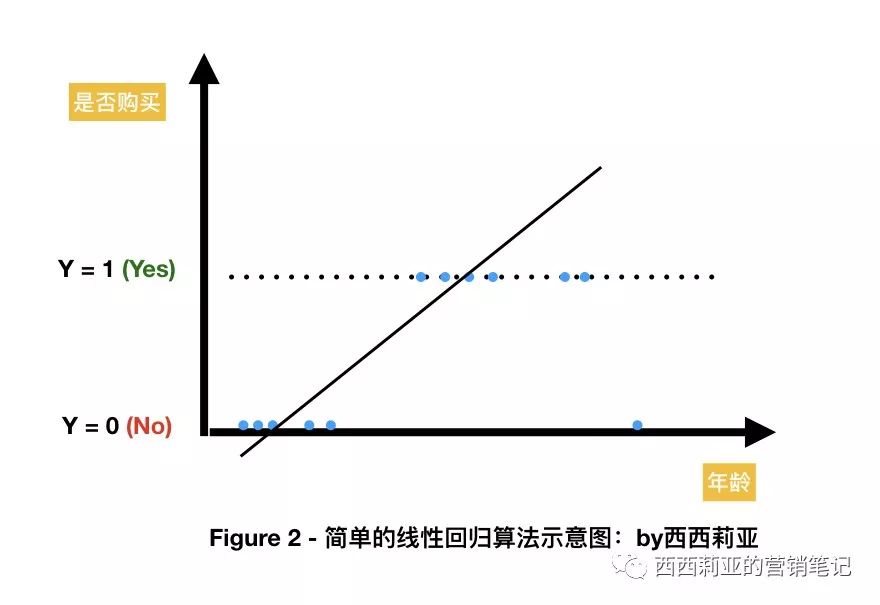

For convenience, we convert "Yes" and "No" into "1" and "0".
In fact, this example is not very good, because the cause variable Y only has two values 0 and 1, is a comparative exception.
Real-life Y is also often a continuous value, such as watching videos often, or the amount d consuming.
In this example, we get a simple one-dollar-a-time equation.
Algorithms, for example, found that the older you get, the more money you have, and the more purchasing power you have.
So you'll push your ads as hard as you can to older people.
But in real life, our Target Audience attributes are not as simple as age.
Think of the X1 / X2 / X3 / X4 / X5 we gave earlier...
Every interest is in oneDimensiondescribes an audience.
For example, (Zhang San, male, 30 years old, single, cat-loving... )。
If there is only one dimension of Age, the fitted result of the algorithm gives us a "straight line" of two-dimensional space.
And if we add "gender" and we have 2 arguments, the algorithm will give us a "face" in three-dimensional space.
Coupled with the "emotional state", we have three arguments, and the algorithm gives us a "body" in a four-dimensional space.
As for five-dimensional, six-dimensional, seven-dimensional... It's some unseerable "shapes."
Each audience, in the world of algorithms, is a "point" that is disassembled into multi-dimensional vector representations.
Machine learning, on the other, is the search for connections and laws between countless scattered points in this vast space.
The end result of the algorithm is a "line" that crosses the "multi-dimensional universe" and can wear the largest number of "stars".
This "line" is the fitting result of machine learning.
In fact, in multi-dimensional space, this is no longer a "line". One can imagine that a line projected on a two-dimensional axis is easier to understand.
When machine learning gets a stable fit, for each new audience, the algorithm analyzes the characteristics of TA and then gets a "line" between the predicted "points" distanceDistance.。
If the distance is zero, which represents the audience perfectly suited to all of our criteria, it's very likely that the Facebook ads algorithm will push the ad in front of him.
The farther away you are, the less likely it is to transform on behalf of this audience. The algorithm then automatically skips him without running an ad for him.
The Learning Phase of Facebook ads is constantly training algorithmic models to find the perfect fit curve. Once the learning is complete, the algorithm looks for the point (potential audience) in the target audience that is closest to the curve.
03
Data! Data!! Data!!!
Whether it's a classification algorithm or a regression algorithm, the most important thing for the algorithm to train the most accurate model is to need enough data.
a / b / - c / d... It is the parameters in this model that do not have fixed values at first, and their values are not calculated until the algorithm has collected enough data.
When you start pushing ads, Facebook's algorithm doesn't have any data (or limited own data in its database), it's just tentatively pushing ads randomly within the target audience of your choice.
Once a user has feedback, such as likes to an ad, or clicks on a purchase link, Facebook collects that user's data into your database.
If we had only a few scattered data, the result would be simpler to fit, and even overfitting.
Simply put, that's itIt is easy to be affected by the data in some special cases, and it is not possible to find more general fitting curves accurately.
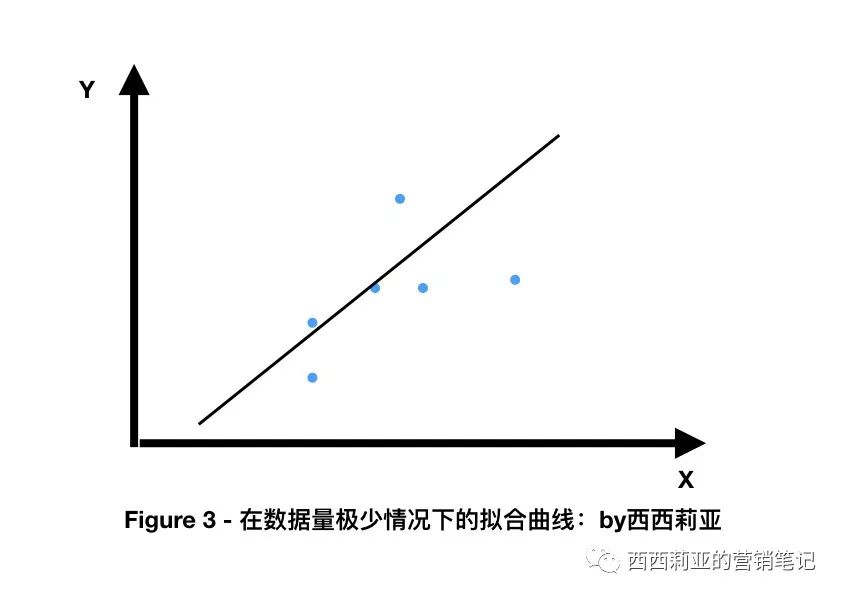
The more data you have, the easier it is to find similarities between these discrete points, making new data more accurate.
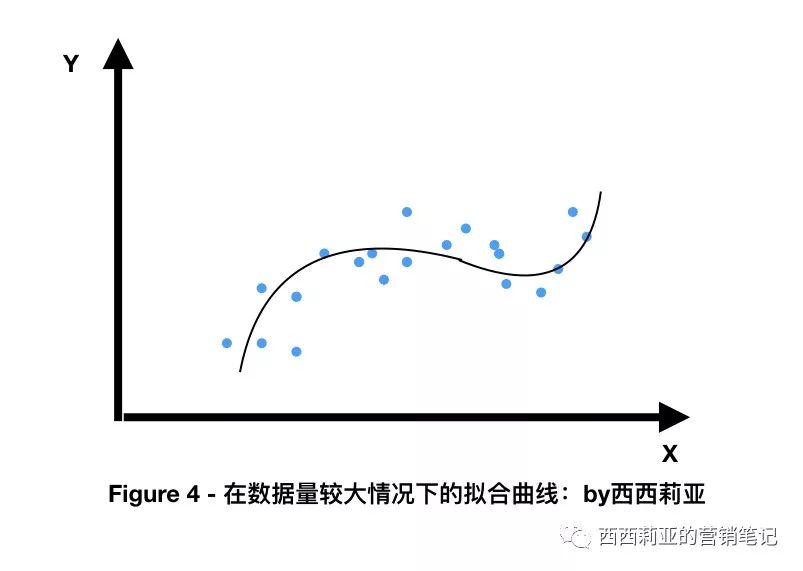
So, smart children's shoes four or four have been trance (early) but (know) big (such as) understand (this),If we get enough data (and enough money), we get a lot of points scattered like stars in the multidivided universe.
Will someone say at this time that you're not talking nonsense? Who doesn't know that advertising is about spending more money.
In one issue of "The Strange Story", Huang said in the debate:
"The real world is made up of a series of random, chaotic, small decisions, and a long chain of cause and effect. A butterfly incites wings and can cause storms in the distance. "
I would like to say that the theory is also true in advertising.
After the advertiser initially chose a target audience, Facebook Ads' algorithm actually started randomly to select the initial audience.
After getting an initial model, the algorithm tries to verify its judgment over and over again by looking for other users with similar characteristics to these users and pushing the same ads.
If the results do not meet expectations, the algorithm adjusts the strategy, such as adjusting the weight of a feature.
In the process of this adjustment, it is necessary to influence the advertiser's decision.
For example, your perfect audience may be girls between the ages of 20 and 25, but you don't have any age restrictions at first, and Facebook may "guess" an audience of 35 to 40 based on the data it already has.
The result ran for a few days, the advertising effect is very poor, the impatient person may stop on this, terminate the advertisement.
In fact, if you hold on a little longer, you can see tomorrow's sun... Ah, no. It's the algorithm that might find a better audience.
Because of randomness, decision-making changes, thus affecting the effectiveness of the entire digital marketing.
Data doesn't lie, but one-sided data can mislead us.
Next, Cecilia discusses how to reduce these chances and uncertainties.
04
So... Should we?
Having said that, what exactly do you have to do to avoid being affected by the uncertainty of some algorithms?
Cecilia's list of points here is the easiest thing I can think of and easiest for an advertising pitcher to notice:
01
Guarantee enough budget
We already know thatThe essence of algorithms is to look for correlations and commonality between data, so simply put, the more data, the better.
But how much data is enough?
I regret to tell you that this is not a "quantitative".
The 5V characteristics of Big Data include Volume, Variety, Velocity, Accuracy, and Value.
But exactly how much "big" can be called big data, academia andNo.A uniform definition.
Similarly, in the end how much advertising data is enough, but also can only see the wisdom of benevolence.
Official Facebook documents say, at least25 to 50 conversionsoptimization is recommended. This should be the minimum requirement for data that is almost required to train the algorithm.
Cecilia advises everyone to do their part. Determine an initial budget based on your capabilities and develop the appropriate KPIs.
If your ads don't work as well as you'd like, adjust your budget or KPIs. If you can't make ends meet, you can try to stop the campaign, change the material of your ad, or adjust your audience to re-run it.
Don't worry about the money you put in before, the money you spent before was the equivalent of buying data with Facebook.
Facebook saves data for 180 days, which means that within 180 days your data can be used by algorithms.
02
Speed up your ads
Theoretically, in the same campaign, if your budget is 1000 knives, then 10 knives a day lasts 100 days and the same amount of data that is bought with 1,000 knives in a day.
In fact, if the algorithm determines that an audience is the perfect audience for your ad, there are many other factors that determine whether to run it to TA.
For example, the Quality Score for advertising, or the Auction algorithm.
High-quality audience and data who want, of course, is the high bidder!
Especially for "buy conversion" target ads, the original audience price is high on average. If your bid is below average, Facebook can only help you find some lower quality leads.
Delayed conversion, the equivalent of not getting effective data, the algorithm on the "smart woman difficult to cook without rice."
Coupled with the time limit for Facebook to store data, Cecilia suggests that instead of "squeezing toothpaste" for 100 days a day, you might as well invest 1,000 knives at a time to get a lot of quality data.
Then use the data you buy to "re-target" and create a "Look Like Audience", which would theoretically work much better.
03
Do not change the delivery strategy frequently
Many impatient children's shoes, advertising out for a day or two, see no effect can not sit still, want to immediately change the material or change the audience.
But... I can't eat stinky tofu!
I understand everyone's mood, feel every minute money is constantly gushing out, heart pain is going to die.
But as a professional advertising pitcher, of course, there must be a longer-term vision and ability!
You have to change your mind and imagine that all this money is going back to your account in a data war. The ̄ is ̄ "").
Algorithms also need data to train a stable delivery model!
Especially at the beginning, the accumulation process from scratch, the algorithm is and its instability (the Learning phase of Facebook's advertising algorithm).
If you adjust your strategy as soon as there is volatility, you're likely to "kill" potential ads and waste some data.
Therefore, advertising should also do a good job of "long-term fishing big fish" psychological preparation, by observing the long-term changes in the data curve to make more realistic predictions and more reasonable adjustments.
Facebook's advertising algorithms are constantly baptized by a mass of data to have confidence in its intelligence.
04
Get the most accurate data possible
Algorithm training requires data, but data and data are not the same Oh!
In the simplest example, the ease of obtaining data is different for different delivery targets.
If it's just a simple PPE, Facebook's advertising algorithm knows which audiences are most likely to interact with ads, and it has the data it needs in its own database.
But if it's Purchase Conversion, the data can only come from your website.
There are a lot of people who say you can run conversion ads directly even if you don't have any initial data.
In previous articles, Cecilia has repeatedly referred to Facebook ads aimed at "impulsive consumers."
So even if it's not the same business or product, impulsive consumers have some common traits.
Facebook can find people with previous buying experience in your target audience, using their data as a training set.
But Facebook doesn't encourage that.
Every ad and product is (should be) unique.
If you use data from another product to train another product's push algorithm, the downside is that it's expensive, data is small, or even biased.
Of course if you're Toho, when I didn't say. As long as you can afford it, you can always buy enough quality data.
Similar questions include, for example, whether to open a "grocery store" or a precise "niche" online store.
The more accurate niche, the higher the flow purity under the same data mass, and the better the training of the algorithm.
For example, a "grocery store" used to sell teeth whitening products, and now it's selling fishing hooks, two completely unfashionable niches.
Even though there have been a lot of purchases before, the data may not be easy to make in the model of training "fish hook ads".
But these problems can also be overcome by classifying the data.
You can set up a category of "tooth whitening buyer" and a category of "fishing enthusiasts" in your own data "warehouse". When running an ad, it's OK to use the data for the appropriate group.
Of course, it is not ruled out that different niche consumers will have similar characteristics, say nothing as good as real money run a few sets of ads to try.
05
The two sides of things
Some people always say that Facebook ads are getting worse and worse, and Cecilia wants everyone to try to see the good side.
Although advertising is getting more expensive and competition is getting fiercer, it is alsoMachine learning algorithms are also getting smarter!
At first, Facebook's demographics were poor with only a few genders, addresses or something. See how many interest features are waiting for you to go to target today!
Countless advertisers are constantly helping Facebook improve its algorithms and target its audience. This is also a benefit for the back-entry!
Besides, Cecilia's long-standing belief is that it's more important to make a good product.
A good product speaks for itself, and advertising just helps it get the message across to those who need it.
So the last positive energy wave: do a good product, do a good marketing.
Keep Calm and Run The Ads!
The audience push mechanism for Facebook ads is not public.
The algorithm is like a black box, you only know your input (set the budget, and set target audience) and then output through the ad algorithm (impression/clicks/video views/conversions... to evaluate and adjust your delivery strategy.
This paper is cecilia's analysis combined with her own subject experience and the search for papers in related fields.
There will be some subjective guesses and opinions, mainly hope to throw bricks and jade, and we explore the "black box" internal working mechanism.
If you can give you some different thinking angle, Cecilia also feel that it is a credit! The core is 😄
1
END
1
Facebook告| Google Adwords| Shopify
The heart has a big future
Fearless of the vast stars and the sea
Internet advertisers are concerned about the public number
👇
Sicilia's marketing notes

Send to the author