El análisis básico de la predicción de la escala de identificación y difusión de usuarios en la era de las redes sociales
Haga clic."Micro Hot Spot WRD"

Céntrese en plataformas de big data
El segundo concurso de minería de datos de comunicación, organizado conjuntamente por el Comité de Investigación de Comunicación Computacional de la Sociedad China de Historia del Periodismo y el Microspot Big Data Research Institute, ha concluido con éxito, con 15 equipos en plena exhibición. A continuación se muestra "Core User Mining and Communication Scale Prediction" seleccionó excelentes obras "Core User Identification and Communication Scale Prediction Analysis in the Social Media Age", presentado por el "Zero Model Team" de la Universidad zhongshan y la Universidad Nacional de Dalian.
Resumen:Con el desarrollo de la plataforma social, el microblog se ha convertido cada vez más en la plataforma de voz de las personas para eventos calientes, y puede tener un amplio impacto en la realidad, y la enorme cantidad de información en micro-blogging a través de la interacción del usuario y el comportamiento de reenvío para difundir, la importancia de la comunicación del usuario mide su peso en todo el proceso de difusión de la información, a través de la identificación de los usuarios principales para predecir la escala de la propagación de un solo micro-blog tiene una importancia científica muy importante. Basado en la compleja teoría del modo de red, este documento utiliza el concepto de grado de nodo para cuantificar la importancia de la comunicación del usuario, y encuentra que el método de cálculo de la importancia del modelo es una mejora y expansión de la importancia de los nodos de red dinámicos tradicionales, y mide de manera más exhaustiva la complejidad de la estructura de la red de comunicación y la importancia multidimensional de los nodos. En segundo lugar, utilizando métodos de aprendizaje automático, el modelo se utiliza para predecir la ley de la comunicación de micro-blogs únicos, y se encuentra que las características de las series temporales son las más eficaces, y ahora la escala de propagación es dominante, mientras que el efecto de predicción de las características de tipo de texto es el peor.
En primer lugar, los antecedentes de investigación y la cuestión se plantea
Con el desarrollo de las redes sociales, los usuarios principales formados espontáneamente por el campo de la opinión pública de micro-blogs no son sólo los miembros centrales de la comunidad de micro-blogs, sino también el centro del campo de la opinión pública de micro-blogging, y el nodo clave de la difusión de la información de eventos públicos repentinos en el micro-blogging, y su existencia juega un papel importante en el mantenimiento de la intensidad de la atención, la difusión de información importante y la orientación de la opinión pública en Internet. En la actualidad, la investigación sobre los usuarios principales se centra en la informática, la gestión de inteligencia, la comunicación de noticias y otras disciplinas, mostrando las características del desarrollo interdisciplinario. En el campo de la comunicación, la investigación de los líderes de opinión de la red se basa en la teoría tradicional de líderes de opinión y el auge de foros, comunidades, blogs, microblogs y otros sitios de redes sociales, que se remontan a 2003 y aumentan año tras año en 2006, especialmente después de 2008. El estudio incluye principalmente los siguientes aspectos; 1. El mecanismo de influencia del líder de opinión de la red. Huffaker cree que los líderes de opinión de la red pueden establecer la agenda e influir en el marco de temas mediante la creación o estimulación de conversaciones sobre un tema en particular. Los académicos nacionales, como Zeng Fansxu, tomaron varios casos de microblogging para eliminar los problemas de derechos, ya que los casos, desde la perspectiva de la teoría de las redes sociales, encontraron que la preocupación de los líderes de opinión condujo a diferencias en el desarrollo de los problemas públicos. Wang Xiuli, por ejemplo, explora cómo los líderes de opinión de la red establecen la agenda e influyen en la orientación de la opinión pública y el comportamiento de actitud de los miembros de la comunidad. 2. El empoderamiento de la red para los líderes de opinión de base y el camino generacional de los líderes de opinión de la red. El análisis de los datos de los rastreadores web basado en la aplicación "Under the Kitchen", como el erudito Cui Kai, encontró que Internet proporciona a la clase de base la oportunidad de convertirse en líderes de opinión, mientras se clasifican sus factores de influencia en categorías autodirigidas y pre-egenidad.
La inteligencia y la informática primero prestan atención a las características de la estructura comunitaria de los usuarios principales, especialmente basadas en diferentes campos y temas, como los principales eventos públicos, rumores y rumores de Internet, etc., se convierten en un tema candente de investigación. En segundo lugar, centrarse en el estudio del propio comportamiento del usuario basado en big data. Como Peng Xiyi a través del uso de análisis de árboles de decisión, análisis de correlación y minería de correlación y otras formas de llevar a cabo análisis estadísticos de usuarios de micro-blogs. Por último, el sujeto se centra en la minería y la identificación de grupos de usuarios. En la actualidad, la dirección de investigación y la base teórica de la minería de usuarios centrales se centran principalmente en 5 direcciones: 1. Utilizando SNA, mediante la obtención de los datos de relación entre los usuarios, la construcción de redes sociales, a través de los diversos indicadores de la red para medir la importancia de los usuarios. La ventaja es que es fácil de entender y el índice es completo, por lo que se convierte en el método principal de investigación de usuarios principales. 2. Utilizando el algoritmo de clasificación de páginas web tradicional PageRank, los usuarios de weibo se consideran páginas tradicionales, y el contacto entre los usuarios se expresa como la relación de entrada y salida entre páginas web, creando así un mapa dirigido entre los usuarios. 3. Sobre la base del algoritmo de nodos de primera, que maximiza el impacto del problema, los antiguos usuarios de K con el efecto más influyente de la difusión final de la información se encuentran a través del análisis característico de los cambios dinámicos de la información de la red social en la transmisión. 4. Construir un sistema de índice de evaluación para evaluar la importancia de los usuarios de microblogging, modelar a los usuarios a través de métodos cuantitativos como el análisis jerárquico, y obtener una calificación de su influencia. 5. Basado en el algoritmo Apiori clásico en el método de regla de asociación.
La escala de la comunicación está estrechamente relacionada con la investigación de los usuarios principales, y hay dos caminos en la investigación actual sobre la escala de la comunicación. El campo de la ciencia de la comunicación se basa en la influencia de la comunicación de las organizaciones de medios de comunicación, y se mide la escala de comunicación de sus "dos micro-extremos". Por ejemplo, Wu Yulan, por ejemplo, al número de fans de weibo y al número total de lanzamientos de micro-blogs como indicador de la escala de la comunicación, a fin de explorar la influencia de difusión de los medios financieros. La inteligencia y la informática prestan atención a la opinión pública de la red desde el punto de vista técnico, especialmente la construcción del modelo de comunicación de la información de rumores y la predicción de la escala de la comunicación. Este es también el enfoque de este artículo.
La base teórica del modelo actual de difusión de información incluye principalmente la teoría de redes complejas, la teoría de redes múltiples y el análisis de redes sociales. Con la teoría gráfica y la física estadística como soporte teórico, la compleja red explora la topología de red y sus características en profundidad. Sus principales características incluyen: 1. que consiste en múltiples nodos o subsímosmos, 2. ser susceptible a influencias ambientales externas e intercambiar constantemente materia, energía e información con el mundo exterior, 3. Bajo ciertas circunstancias, hay un vínculo entre los nodos dentro de la red e interactuar entre sí, afectando así entre sí, y 4. La interacción entre nodos y la existencia de alguna relación no lineal compleja con todo el sistema. Con la profundización de la investigación en redes sociales, los estudiosos encuentran que no es sólo una red compleja de un solo nivel, por lo que plantean el concepto de múltiples redes, es decir, una estructura de red tiene una red multicapa. El método de análisis de redes sociales considera que toda la red está compuesta por varios nodos, cada uno de los cuales tiene una determinada relación de enlace, y la relación de enlace dentro de la estructura de red determina la vía de comunicación de la información y sus características.
En resumen, este documento encuentra que hay dos perspectivas distintas sobre el estudio de los usuarios principales y la escala de la comunicación. La perspectiva de la comunicación se centra en la relación entre las personas y la sociedad en el proceso de comunicación, analiza cómo la estructura social y la nueva tecnología de los medios de comunicación afectan a la generación de usuarios centrales y la reacción de los usuarios principales a la sociedad política; La inteligencia y la informática prestan más atención a las características y la relación entre el usuario principal como nodo y toda la estructura de la comunidad, así como el mecanismo interno del desarrollo de la comunicación de opinión pública. Su método es más riguroso, el modelo matemático es completo, pero carece de la interpretación de la causa del fenómeno. Basándonos en la investigación anterior, hacemos las siguientes preguntas:
Pregunta uno del estudio:En los eventos de puntos de acceso de red, ¿cómo podemos identificar con precisión a los usuarios principales que desempeñan un papel importante en el evento?
Pregunta de estudio dos:¿Cuáles son las características de los usuarios principales en los eventos de punto de acceso de red?
Pregunta de estudio tres:¿Qué factores pueden afectar la escala de difusión de la información?
En segundo lugar, los métodos de investigación y el preprocesamiento de datos
2.1 Descripción de datos y preprocesamiento
Este documento utiliza un conjunto de datos de difusión de información de micro-blogs a gran escala. En el conjunto de datos, se rastrearon 26.998 fuentes, con más de 17,84 millones de retweets, lo que implica alrededor de 8 millones de usuarios y más de 700 millones de relaciones de usuario a usuario. El conjunto de datos se divide en tres partes: el usuario presta atención a los datos de relación, reenvía los datos de relación y los datos de texto del microblog de origen. Entre ellos, los datos de relación de seguimiento del usuario contienen una lista de usuarios y los usuarios que siguen, los datos de relación de retweet de micro-blogs contienen el identificador de microblog, el usuario retweeted, el usuario que generó el comportamiento de retweet, el tiempo de retweet y la hora del tiempo de liberación del microblog de origen y el contenido retweet del microblog, los datos de texto de micro-blogs de origen contienen el identificador de microblog de origen, el identificador de autor de weibo, el tiempo de publicación de micro-blogs y el contenido de microblog.
El interés de un usuario en una red de relaciones y una red de reenvío puede reflejar la influencia del usuario en las redes sociales. Los datos de la relación de interés se procesan en un formato de datos capaz de la construcción de la red, y se establece la red de atención del usuario, basado en la relación de reenvío de todos los micro-blogs, se utiliza una red de reenvío como nodo de inicio, el retweeter es el nodo de destino, una red de reenvío se construye para medir la influencia del usuario en la red de reenvío, y un solo micro-blogging datos se basa en el autor de micro-blogs como el nodo de inicio, y el retweeter es el nodo de destino, y se construye un único árbol de comunicación de micro-blogs.
2.2 Métodos básicos de identificación de usuarios
2.2.1 Definición de la modalidad de emisión y viral
Definición 1. Motivo de difusión. Como reflejo del efecto de difusión en el proceso de difusión de la información, es el componente principal de la estructura de la red estelar, en la que la característica de propagación de difusión es causada por un único nodo influyente, y su estructura es la estructura del módulo de tres nodos en la Figura 1 (a). El grado de modo de difusión de la red es el índice de cantidad del modo de difusión contenido en la red.
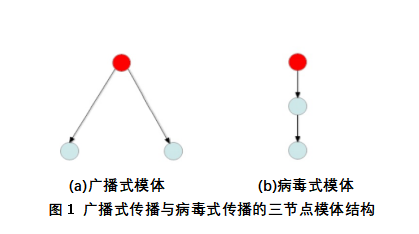
Definición 2. Motivo viral. Refleja el efecto viral en el proceso de transmisión de información, que incluye una estructura de ramas multigeneracional en la que los nodos afectan directamente sólo a las ramas adyacentes, y su estructura principal es la estructura del módulo de tres nodos en la Figura 1 (b). El grado de modo de virus de la red es el índice del número de modos de virus contenidos en la red.
Definición 3. Grado de motivo. Dada una estructura de red con propagación G(V, E), V para el conjunto de nodos, E para conjunto de bordes, a∈V, por cualquier nodo a de la red como nodo raíz, a puede formar una estructura del módulo de transmisión de difusión y estructura del módulo de transmisión viral El índice de cantidad, es decir, el número de modos de difusión y módulos virales que se pueden formar con nodos rojos como los nodos raíz de la Figura 1, se registra como modo de difusión de nodo BM y módulo viral de nodo VM, por lo que el indicador se compone de dos valores. Los resultados se guardan en un conjunto binario (BM, VM). El pseudocódigo del algoritmo para la modalidad de nodo se muestra a continuación.

2.3 Métodos de predicción de escala de propagación
2.3.1 Definición de problemas predictivos
El estudio intentó predecir la escala de la futura propagación de un tweet observando sus retweets dentro de una hora de su lanzamiento. En nuestros datos, la mayoría de los tweets rara vez se retuitean después de 72 horas de publicación, por lo que este estudio define el problema de predicción como el retweeting de un tweet conocido dentro de una hora de su lanzamiento, prediciendo la escala de transmisión en los próximos 75 minutos, 195 minutos, 315 minutos,..., y 4380 minutos.
2.3.2 Método de análisis de correlación basado en el coeficiente de información máximo
Maximal Information Coefficient (MIC) es un novedoso método de correlación basado en información mutua para grandes conjuntos de datos, que fue publicado en la revista Science en 2011. Este método es superior al coeficiente de correlación tradicional de Pearson, que puede determinar la relación de función o la relación no de función entre variables y, a continuación, obtener la influencia de la variable en el conjunto de datos. El cálculo MIC se divide en tres pasos: dado i, j, la composición XY del gráfico de dispersión i columna j fila mallado, y averiguar el valor máximo de información mutua, y luego se normaliza el valor de información mutua más grande, y finalmente seleccionar el valor máximo de la información mutua en diferentes escalas como valor MIC. La fórmula se define de la siguiente manera:
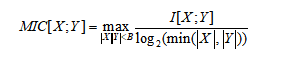
Donde, . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . X.. Y's indica cuántos segmentos se dividen en las direcciones X e Y en la cuadrícula del gráfico de dispersión, respectivamente X El valor es un valor empírico que el número total de cuadrados en todos los cuadrados no puede ser mayor que los cuadrados 0,6 o 0,55 de la cantidad total de datos tomados por beta.
MIC tiene las características de universalidad, equidad y simetría. La universalidad de MIC se refiere a su capacidad para explorar una amplia variedad de relaciones de función en una muestra sin limitar el tipo de función (por ejemplo, funciones lineales, funciones de recuento, etc.). En resumen, se pueden incluir casi todas las relaciones funcionales; la equidad de MIC significa que MIC puede dar coeficientes similares para las relaciones funcionales y no funcionales con el mismo nivel de ruido. La simetría de MIC se refiere a MIC (X, Y) y MIC (Y, X), porque depende solamente del tipo de datos, y el MIC es constante en el eje de transformación de orden, donde IF representa la distribución de probabilidad en F.
2.3.3 Basado en el método de clasificación de características del modelo XGBoost
XGBoost es un modelo de árbol potenciado por gradiente. En comparación con el GBDT clásico, XGBoost ha realizado algunas mejoras, lo que resulta en mejoras significativas en el rendimiento y el rendimiento. GBDT expande la función de destino Taylor al primer orden, mientras que XGBoost expande la función de destino Taylor al segundo orden, conservando más información sobre la función de destino, que es de gran ayuda para mejorar el efecto. Además, XGBoost añade elementos de normalización L2 para ayudar al modelo a lograr una menor varianza. Además de la diferencia entre la teoría y el GBDT tradicional, el concepto de diseño de XGBoost tiene principalmente las siguientes ventajas: rápido, portátil, menos código, tolerancia a fallos.
El método de ordenación de características basado en el modelo evalúa principalmente las ventajas y desventajas del subconjunto de entidades según el rendimiento previsto del modelo de algoritmo. Usando el algoritmo de aprendizaje automático XGBoost, cada característica se puede calificar durante el entrenamiento, mostrando así la influencia de cada característica en el entrenamiento del modelo. En el algoritmo XGBoost, la puntuación de características se puede considerar como el número de veces que se utiliza para separar el árbol de decisión, y cuanto mayor sea la puntuación de la característica, más importante será la característica y mayor será el impacto en el rendimiento del algoritmo.
En tercer lugar, los hallazgos y resultados
3.1 Análisis de la importancia del nodo basado en la difusión y la modalidad viral
Para cada "microblog de origen" en el conjunto de datos, este artículo utiliza primero sus datos de reenvío para crear una red de reenvío (el autor del microblog es el nodo inicial, el reenviador es el nodo de destino). En segundo lugar, se calcula el índice de modalidad de nodo para cada usuario en la red de propagación. Por último, la modalidad de nodo de cada usuario es secuencial (es decir, modo de difusión más modalidad viral) y ordenada de grande a pequeña.
La Figura 2 muestra la distribución de una red de micro-blogging y indicadores de modalidad de nodo. El contenido de la publicación del microblog raíz se trata principalmente de la discusión de "un documento de examen de posgrado universitario". Se han procesado apodos de usuario específicos en el conjunto de datos, y este artículo está representado por letras. El cuadro 2 a) es el diagrama de estructura de red de la red de comunicación de microblogging, el nodo rojo A representa el publicador del microblog, el nodo púrpura representa al usuario con una modalidad de nodo mayor que 0 y el nodo azul representa a un usuario con una modalidad de nodo igual a 0. La información de Weibo se transmite en el orden del usuario A-B-D-E-C. Como se puede ver en la figura, el lanzamiento de "microblog fuente" ha recibido un gran número de retweets, y su estructura de red toma la forma de un diente de león. Tres usuarios de nodo importantes, B, D y E, se derivan del usuario de la versión A. Mensajes weibo se retuitean en grandes cantidades en el usuario B y D, y sus estructuras de red también están en forma de diente de León. Y la información de micro-blogging en el usuario E no sólo obtuvo una gran cantidad de retweets, sino que también obtuvo una profundidad más profunda de comunicación, y la información de micro-blogging del usuario E al círculo de fans del usuario C, al mismo tiempo obtener un gran número de retweets.
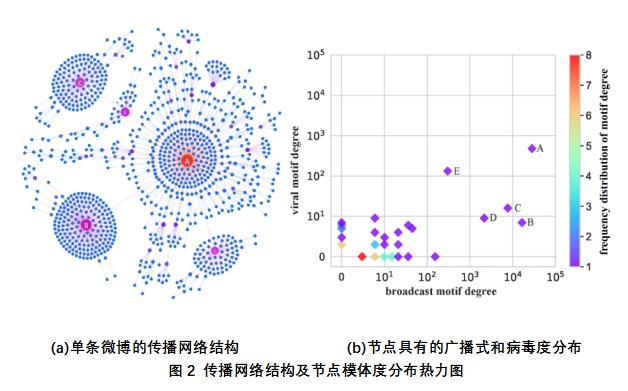
La figura 2 b) muestra la distribución del índice de modalidad de nodo de este microblog, el eje horizontal representa el grado de modo de difusión del nodo, el eje de coordenadas representa el grado de modo viral del nodo y el usuario con el índice de modalidad de nodo es cero no se muestra. La barra de color de la figura refleja la distribución de frecuencia de usuario con la misma modalidad de nodo y el color del nodo se acerca al rojo, lo que indica que cuanta más frecuencia aparezca el usuario en un determinado grado de modo. A medida que el color del nodo se acerca al púrpura, el número de nodos en una determinada modalidad es menor. Se puede ver en la figura que la distribución del índice de modalidad de nodo se divide generalmente en dos partes debido a la diferencia de la propia contribución de los usuarios diferentes a la propagación.
La primera parte son los usuarios en la parte inferior izquierda de los ejes, que tienen un menor número de módulos de difusión y virales, correspondientes a los nodos morados de la Figura 2 (a) que no indican letras. La segunda parte son los cinco usuarios A, B, C, D, E en el lado derecho de los ejes. Estos usuarios tienen un índice de modalidad de nodo más amplio, lo que indica que la contribución a la difusión de información es grande, básicamente liderando la difusión de información.
3.2 Análisis de los resultados de las múltiples características multiestrella que afectan a la difusión de información
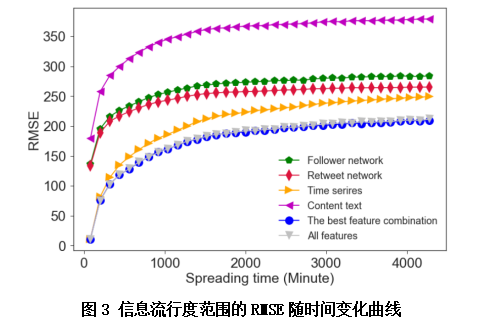
En este estudio, se construyeron cuatro factores principales que afectan a la difusión de la información, entre ellos el enfoque en las características estructurales de la red de relaciones (red de seguidores), las características de la red retweet, las características de las series temporales y las características de texto de contenido, para un total de características de 82 dimensiones (véase el apéndice para descripciones específicas de características y símbolos descriptivos). La Figura 3 muestra los resultados de predicción de varias combinaciones de entidades, con el eje X que representa el tiempo de propagación y el eje Y que representa el indicador de evaluación RMSE. Cuanto menor sea el valor del indicador, menor será el error entre el valor predicho y el valor verdadero, y mayor será la precisión de la predicción. En general, con el aumento del tiempo de propagación, el rendimiento predictivo de varias características disminuye gradualmente. Entre las cuatro características construidas, los resultados de predicción de las características de texto de micro-blogs son los peores, seguido de las características de la estructura de la red de relaciones y la estructura de la red de reenvío. El rendimiento predictivo de las características de series temporales es mejor, especialmente durante períodos de 75 a 500 minutos, cuando la curva RMSE de las características de la serie temporal se vuelve a producir con las curvas de casi todas las entidades. También se encuentra que el RMSE de la característica de 12 dimensiones después de la selección de características está casi totalmente ajustado a la curva de todas las entidades a lo largo del tiempo, es decir, el efecto de predicción ideal sólo se puede lograr mediante la selección de características de características de 12 dimensiones. En otras palabras, teniendo en cuenta que solo estas características tridimensionales en la práctica pueden reducir la complejidad del modelo, evitar el ajuste excesivo, reducir el tiempo de cálculo y mejorar la precisión de las predicciones.
Con el fin de analizar la influencia de diversas características en diferentes períodos de propagación, este estudio dividió el proceso de difusión de información en tres etapas: inicial (T-75 minutos), medio plazo (T-2275 minutos) y posterior (T-4275 minutos), y extraído del modelo XGBoost entrenado el orden de importancia de estas tres características del período. La Figura 4 muestra el orden de importancia de las características Top20 durante los tres períodos de difusión de información. En las primeras etapas de la difusión de la información, las características de las clases de series temporales estaban generalmente en la parte superior de la lista, especialmente las características scaleT60, PF y escala T59, que obtuvieron una puntuación significativamente mayor en importancia característica que otras características. En la etapa media y tardía de la difusión de la información, la posición superior son las características de la clase de estructura de red y las características de la clase de texto de micro-blogging, y las puntuaciones de influencia de estos dos tipos de características no son muy diferentes, casi distribuidos más de 600. La posición de la característica de las series temporales comenzó a disminuir, la más obvia es la característica scaleT60, su puntuación de importancia característica bajó de 1001 a 416. En resumen, las características de las series temporales son los factores clave que afectan a la escala de difusión de la información.
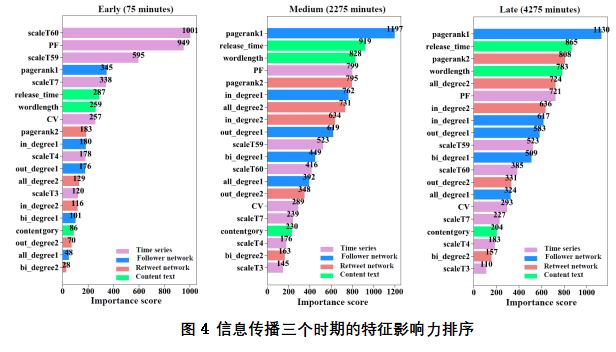
Conclusiones y debates
La complejidad de la red de micro-blogs reales, las múltiples relaciones dentro y fuera de línea, las diferencias en la relación de enlace de estructura de subred, las características personalizadas del usuario, las diversas categorías de información han añadido complejidad a las propiedades de la red de micro-blogging. El uso de una única estructura de red para estudiar la difusión de información de micro-blogs obviamente no es lo suficientemente práctico, la aplicabilidad práctica de los resultados de la investigación no es fuerte. Por lo tanto, el uso del big data para analizar las características básicas de las redes de micro-blogs, y la introducción de redes complejas y conceptos multi-red, de modo que toda la red de micro-blogging no sólo tiene las características del mundo pequeño y ninguna escala y otras redes complejas, sino también las características de estructura de red en línea y fuera de línea de múltiples redes. En este documento, se propone un método de análisis cuantitativo de la importancia de la comunicación de los usuarios de redes sociales basado en la estructura del módulo, y el grado de modo bidimensional del usuario en la red de comunicación de micro-blogs y cada microblog se cuantifica sobre la base del modo de difusión y el grado de modo viral, que representa cuidadosamente las características de propagación de los nodos, y analiza el mecanismo de comunicación de la información en la red de micro-blogs en función de las características de la modalidad de nodo. Al mismo tiempo, basado en el marco de aprendizaje automático, se construye un nuevo paradigma para estudiar los factores de influencia de la difusión de la información, que implica tres pasos: ingeniería de características, selección de características y criterios de evaluación. En primer lugar, el modelo XGBoost se utiliza para ordenar la influencia característica de cuatro categorías, averiguar los principales factores de influencia de diferentes características de categoría, y de acuerdo con el coeficiente de información máximo, el análisis de la relación de correlación y la clasificación de la importancia de la característica de las cuatro categorías de características se llevan a cabo, y se filtra la combinación óptima de características. Comparando los resultados de la predicción de la prevalencia de información multicanal, se constata que la precisión de la predicción del rango de prevalencia de la información disminuye con el aumento del tiempo de propagación de la información a lo largo del proceso de difusión de la información, en el que las características de las series temporales desempeñan un papel clave en la predicción de la difusión de la información.
Apéndice.
1.1 Centrarse en el análisis de características de la categoría de red de relaciones
La influencia social del editor de información tiene una fuerte influencia en la popularidad de la información de micro-blogging, que se refiere a un fenómeno en el que el usuario influye en las opiniones, emociones y comportamientos de los demás. Bakshy y otros analizaron la relación entre la influencia de los usuarios en Twitter y Twitter retweets, y encontraron que los editores de temas candentes eran generalmente usuarios de alto impacto, y que otros tweets de tales usuarios también tenían retweets más altos. Zhang y otros analizaron los retweets de miles de usuarios de Sina Weibo y descubrieron que cuantos más suscripciones reciban los usuarios, más retweets obtendrán en sus microblogs. En vista de la influencia de estas características de estructura de red, este documento utiliza datos de relación de atención al usuario preprocesados para construir la red y extrae las características de red de los cinco nodos de microblogging de la Tabla 1 como características de la predicción de popularidad de la información.

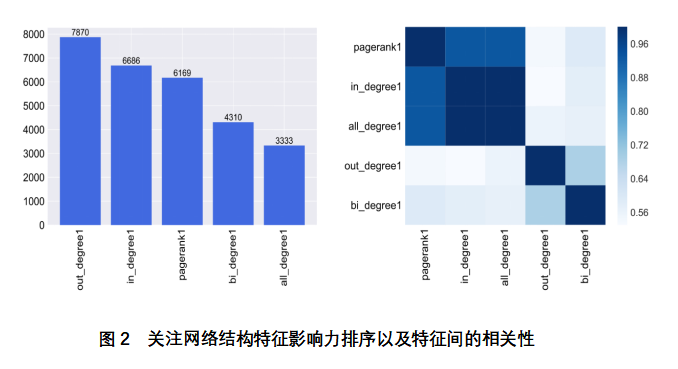
Basado en el algoritmo XGBoost, el subgrafo en el lado izquierdo de la Figura 2 muestra el orden de las influencias que se centran en las características estructurales de la red de relaciones, y el eje Y es la puntuación de importancia característica. Como se puede ver en la figura, los valores fuera de rango, feed-in y PageRank de los usuarios de los microblogs de origen tienen un mayor impacto en la popularidad de la difusión de información, mientras que los efectos bidireccionales y todo en uno de los usuarios de los microblogs de origen tienen un menor impacto en la popularidad de la información, y las puntuaciones de importancia de las dos características son muy diferentes de las de los tres primeros. Se puede ver que en la red de preocupación, el grado bidireccional del nodo y el grado del nodo no pueden cuantificar con precisión la influencia del usuario. En la figura del lado derecho de la Figura 2, la correlación entre las características de esta categoría se calcula sobre la base del coeficiente de información máximo. Las cinco estadísticas de características se dividen en dos colecciones, la primera de las cuales contiene el valor PageRank, el grado de entrada y todos los grados del nodo, que son muy relevantes y tienen un coeficiente de información máximo de cerca de 1, ya que las tres entidades se ven afectadas por el número de ventiladores de nodo. La segunda colección contiene el número de nodos y el número de amigos bidireccionales, y también hay una fuerte correlación entre ellos, principalmente porque la cantidad de estas dos características está determinada por el número de amigos del nodo. En general, la primera colección es más relevante que la segunda.
Combinado con el análisis anterior, este documento selecciona primero out_degree1, in_degree1 y pagerank1 como las principales características de categoría de la red de relaciones de acuerdo con el análisis anterior, ya que las puntuaciones de influencia de estas tres características se distribuyen principalmente entre 6000 y 8000, mientras que las bi_degree1 y all_degree1 se distribuyen entre 2500 y 4500, la brecha es grande. En segundo lugar, según la imagen correcta se constató que la correlación entre Pagerank1, indegree1 y all_degree1 es mayor que 0.9, hay una fuerte redundancia entre sí, teniendo en cuenta la puntuación de influencia característica in_degree1 y pagerank1 está cerca, el papel desempeñado en el proceso de difusión de información también está cerca, por lo que la puntuación de impacto característica de 6686 in_degree1 características en lugar de la puntuación de 6169 pagerank1 características. Por último, establezca la combinación óptima de características de clase de red de relaciones en out_degree1 y in_degree1.
1.2 Análisis de características de la categoría de red directa
En comparación con prestar atención a la red de relaciones, la construcción de las características de la estructura de red de reenvío se basa en la topología de red dinámica y el comportamiento dinámico del usuario. Kupavskii y otros, al predecir el tamaño en cascada de los mensajes de microblogging en Twitter, sugieren que la influencia del usuario se mide utilizando el valor PageRank del usuario en la red de reenvío, y que la introducción de esta característica mejora el poder predictivo del modelo. Para representar la relación y la influencia entre los reenviadores, este documento crea otras características estructurales de la red de reenvío, como se muestra en el Cuadro 2, además de las características de valor PageRank del nodo de construcción de datos de usuario de reenvío.

La Figura 3 muestra la correlación entre la clasificación de la influencia de las características de la estructura de la red de reenvío basada en el modelo XGBoost y las características basadas en el coeficiente de información máximo. La figura de la izquierda muestra el orden de influencia de las características de la estructura de la red de reenvío, y el eje Y representa la puntuación de importancia de las entidades. De la figura de la izquierda, puede ver que las cuatro características de la entrada de nodo, todos los grados, el valor de PageRank y el nodo fuera de la red de reenvío tienen el mayor impacto, mientras que el número de amigos bidireccionales del usuario tiene el menor impacto. En la figura de la derecha, se puede encontrar que, al igual que la red de preocupación, el valor MIC de la colección del valor pageRank, el grado entrante y todos los grados del usuario en la red de reenvío es mayor que 0,76, es decir, hay una fuerte correlación entre ellos. En general, la primera colección es más relevante que la segunda.
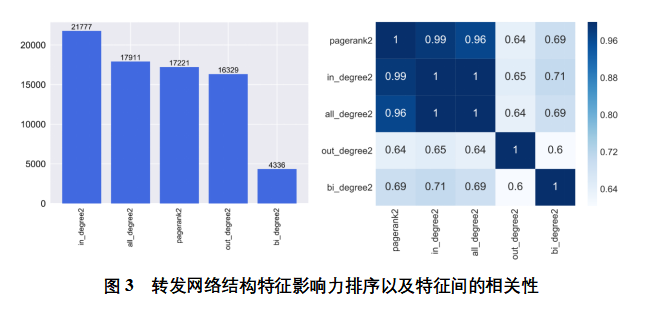
En combinación con el análisis anterior, in_degree2, all_degree2, pagerank2 y out_degree2 se distribuyen principalmente entre 15.000 y 25.000, mientras que las puntuaciones de influencia de bi_degree2 son solo 4366. Por lo tanto, este documento en primer lugar, las características 4D como la combinación óptima de características de red de reenvío. Sobre la base del análisis de correlación de la figura de la derecha, se encontró que había una alternativa fuerte entre pagerank2, in_degree2 y all_degree2, y que no había mucha diferencia entre la influencia de all_degree2 y pagerank2, por lo que se utilizó la puntuación de influencia de all_degree2 en lugar de la puntuación de influencia de 17221 pagerank2. out_degree2 entre los datos y otras características es baja, más independiente y no eliminada. Por último, las in_degree2, all_degree2, out_degree2 se establecen en la combinación óptima de la clase de red de reenvío.
1.3 Análisis de características de categoría de serie temporal
Las series temporales tienen una fuerte influencia en la popularidad de la información. Yang et al. estudiaron el patrón de desvanecimiento de la prevalencia de contenido generado por el usuario con el tiempo, y excavaron 6 patrones de tiempo de popularidad de diferentes formas. Hu y otros analizaron la serie temporal de popularidad de temas candentes en brotes a corto plazo y descubrieron que sólo se necesitaba una pequeña cantidad de datos históricos para predecir con precisión la prevalencia de temas. Al mismo tiempo, con el fin de medir la explosividad de la serie temporal, se construyen la relación de pico (fracción de pico, PF) y el coeficiente de variación (Coeficiente de variación, CV). Entre ellos, el pico máximo se define como la escala de difusión en eventos unitarios con el mayor crecimiento neto. La relación de pico es la relación entre el pico y la escala de difusión total S, es decir,
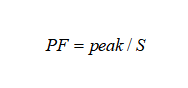
El coeficiente de variación mide la estabilidad de toda la curva de difusión, que se define como la desviación estándar de la serie temporal δ y la relación de los medios, es decir,
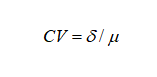
En vista de la influencia de las características de las series temporales en la prevalencia de la información, se utilizan tres características de series temporales en el Cuadro 3 como características de la predicción de la prevalencia de la información.
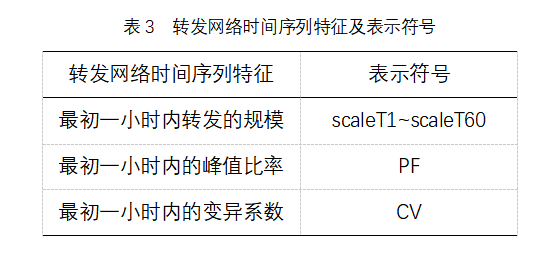
La Figura 4 muestra la correlación entre el orden de las influencias de la característica de serie temporal basada en el modelo XGBoost y las características basadas en el coeficiente de información máximo. Debido al gran número de entidades de esta categoría, las primeras entidades de 20 dimensiones después de la ordenación de entidades se seleccionan para el análisis. El subgráfico izquierdo de la Figura 4 muestra la clasificación de influencia de la entidad de serie temporal y el eje Y representa la puntuación de importancia de la entidad. Se puede encontrar en la figura de que la escala de propagación inicial, la relación máxima y el coeficiente de variación de los microbúbricas tienen una gran influencia en la difusión de la información. La escala de transmisión en los minutos 59 y 60 (ScaleT60 y Scale T59) llegó en la parte superior, principalmente debido a la fuerte correlación entre las dos entidades y el primer objetivo de predicción (ScaleT75). El subfilo a la derecha de la Figura 4 muestra la correlación entre las características de las series temporales y encuentra una correlación menor entre la escala inicial de propagación de microbúbricas y una correlación más fuerte entre la escala de propagación en los momentos siguientes. Las relaciones de pico y los coeficientes de variación tienen una baja correlación con otras variables.
En combinación con el análisis anterior, las primeras entidades de 20 dimensiones después de la clasificación de entidades XGBoost se utilizan primero como los principales factores de este tipo de entidad. Según el análisis de la correlación característica en la imagen correcta, se encuentra que la correlación entre las características de la escala de propagación es mayor que 0,8, que puede ser reemplazada entre sí. ScaleT1 y scaleT2 tienen puntuaciones de influencia característica de 546 y 529, respectivamente, en el segundo y tercer lugar en el ranking de influencia característica, y la influencia de las dos características es casi la misma, por lo que el uso de scaleT2 en lugar de scaleT1. Del mismo modo, podemos reemplazar la característica de escala de propagación posterior con la escala de cuarto lugar T60. Las características pf y CV tienen una correlación baja con otras características y no se eliminan. Por último, PF, CV, scaleT2 y scaleT60 se convierten en combinaciones óptimas de características de categoría de series temporales.
1.4 Análisis de características de la categoría de texto weibo
El contenido de texto de weibo tiene una gran influencia en la popularidad de la información de microblogging. Por ejemplo, cuando una estrella lanza su último álbum de canciones, el tweet generalmente obtiene millones de retweets. Algunos microblogs de clase de noticias tienen menos retweets. Hong y otros utilizaron el modelo de tema para clasificar el contenido de texto de los microblogs, y analizaron la relación entre las categorías de contenido de texto y los retweets de micro-blogging. En un sistema de microblogging, un microblog generalmente contiene una variedad de información multimedia, como hipervínculos, videos, imágenes, etc. Suh y otros analizaron una gran cantidad de datos de Sina Weibo y encontraron que el número de hipervínculos y etiquetas tenía una fuerte correlación con si la información de micro-blogging fue reenviada. Zhao y otros encontraron que en comparación con el microblogging de solo texto, los microbúblicos que contienen información multimedia como videos e imágenes tienden a tener una mayor cantidad de retweets y un tiempo activo más largo. Los hallazgos como Bao tienen una mayor tasa de menciones de los usuarios con una gran base de fans que otros usuarios. Teniendo en cuenta la influencia de estas características de texto, este documento utiliza las características de texto de la Tabla 4 como características de la predicción de la prevalencia de la información. Para las características de categoría del contenido de texto del microblog, la categoría de tema del contenido de texto se divide mediante el modelo de tema LDA.

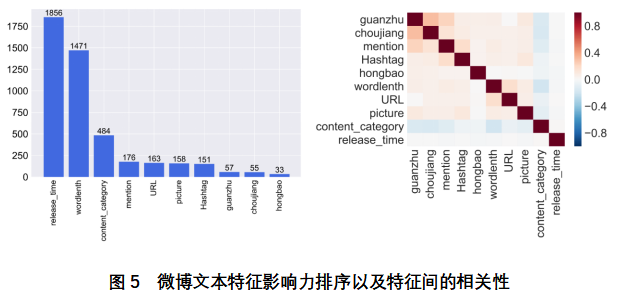
La Figura 5 muestra la clasificación de la influencia de la característica basada en el modelo XGBoost y el análisis de correlación característica basado en el coeficiente de Pearson. La figura de la izquierda muestra el orden de la influencia de las características del texto de microblogging, y el eje Y es la puntuación de importancia de las características. A partir de la figura se puede twittear el tiempo de lanzamiento, la longitud del texto, la categoría de contenido de las tres características del mayor impacto, y si se debe incluir sobres rojos, si se debe incluir sorteos y otras características casi sin impacto en la predicción de la popularidad de la información. La imagen de la derecha muestra la correlación entre las características del texto de microblogging, y se puede encontrar que la correlación entre las 10 entidades es muy baja, lo que indica que las características son casi independientes entre sí.
Teniendo en cuenta que la correlación entre estas características tridimensionales es baja, y que las puntuaciones de influencia de las características tridimensionales de realse_time, wordlenth y content_category se distribuyen principalmente alrededor de 400 a 1900, mucho más altas que las características tridimensionales de las fracciones de influencia distribuidas entre 0 y 200. Por lo tanto, este artículo realse_time, wordlenth, content_categor como la combinación óptima de características de clase de texto de micro-blogging.
1.5 Combinación óptima de características
En los cuatro subseiles anteriores, este documento analiza la clasificación de influencia característica y la correlación de las características de cada categoría, y obtiene la combinación óptima de varias características, desde las características originales de 82 dimensiones hasta las 12 dimensiones actuales, los detalles se muestran en la Tabla 5.

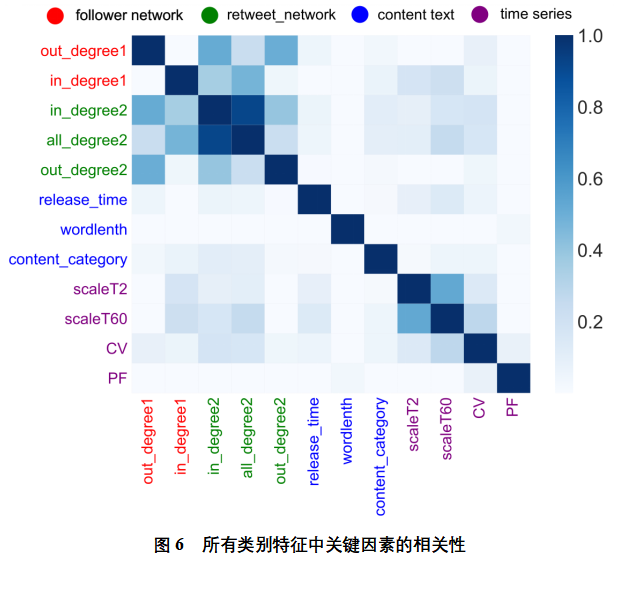
Esta sección se centra en el análisis relacionado con las características y la clasificación de influencia entre categorías para entidades en la Tabla 5. Como se muestra en la Figura 6. Como se puede ver en la figura, estas características tridimensionales se dividen aproximadamente en dos colecciones, la primera de las cuales contiene características clave que se centran en las características estructurales y las estructuras de red de reenvío, principalmente porque se ven afectadas por la estructura de los nodos, de las cuales all_degree2 y in_degree2 son las más relevantes, cerca de 1.0, mientras que la correlación entre las entidades restantes es inferior a 0,5. El segundo conjunto contiene características clave de la clase de serie temporal, incluidas scaleT60, scaleT2 y CV. Existe una correlación entre scaleT60 y scaleT2, que está cerca de 0,5, principalmente porque están influenciados por factores de tiempo. Las características de la clase de texto de Weibo no están relacionadas con otras características de categoría y son independientes entre sí. En general, la mayoría de las entidades redundantes se han filtrado después de la selección de entidades dentro de la categoría. Con all_degree2 y in_degree2, las características restantes están esencialmente débilmente relacionadas o independientes entre sí. Por lo tanto, la característica actual se puede pasar al modelo para la predicción.
Referencias al apéndice
Wang Ping, Xie Yu-till. Estudio empírico de los líderes de opinión de Weibo en incidentes públicos repentinos - Tome "Accidente de coche de Wenzhou" como ejemplo . . . Comunicación moderna (Journal of China Media University), 2012, 34 (03): 82-88.
[2] Katz E.The two-step flow of communication:An up-to-date report on an hypothesis[J].Public Opinion Quarterly, 1957, 21 (1) :61-78.
[3] Eirinaki M, Monga S P S, Sundaram S.Identification of influential social networkers[J].International Journal of Web Based Communities, 2012, 8 (2) :136-158.
[4] LIM S H,KIM S W,PARK S,et al. Determining content power users in a blog network:an approach and its applications[J]. Systems,Man and Cybernetics,Part A:Systems and Humans,IEEE Transactions on,2011,41(5):853-862.
[5] AKRITIDIS L,KATSAROS D,BOZANIS P. Identifying the productive and influential bloggers in a community[J].Systems,Man,and Cybernetics,Part C:Applications and Reviews,IEEE Transactions on,2011,41(5):759-764.
He Li, He Yue, Ho Yeqing. Weibo User Feature Analysis and Core User Mining . . . Intelligence Theory and Practice, 2011, 34 (11): 121-125.
Wang Ping, Xie Yu-till. Estudio empírico de los líderes de opinión de Weibo en incidentes públicos repentinos - Tome "Accidente de coche de Wenzhou" como ejemplo . . . Comunicación moderna (Journal of China Media University), 2012, 34 (03): 82-88.
Zeng Xu, Huang Guangsheng. La composición, vinculación y el impacto político de la Comunidad de líderes de opinión de Internet: Tome Weibo como ejemplo de la era abierta, 2012, (04): 115-131.
Wang Xiuli. Estudio sobre el Mecanismo de Influencia de los Líderes de Opinión Comunitaria en Línea - Tome la Pregunta Social y responda a la Comunidad "Saber" como Ejemplo de la Prensa Internacional, 2014, 36 (09): 47-57.
Cui Kai, Liu Dexuan, Yan Xidi. Grassroots Opinion Leaders Network Social Capital Accumulation Path Study - Análisis de datos de reptiles web basado en la comunidad alimentaria en línea "Under the Kitchen", 2020, (02): 64-74.
Lin Ping, Wang Xiaomei, Wei Jing. Análisis de la Red de Colaboración de Líderes de Opinión basado en Comparaciones de Estructuras Comunitarias, Ciencias Sociales Ningxia, 2020, (02): 193-205.
Peng Xiyi, Zhu Qinghua, Liu Wei. Análisis de características de usuario de micro-blog e investigación de clasificación: tome Sina Weibo como ejemplo. Ciencias de la Inteligencia, 2015, 33 (1): 69-75.
Zhu Linghui, Qian Peng. Basado en el sitio de intercambio de vídeo de impeachment de bilibilibili, Core User Group Characteristics Research, 2020, (03): 16-23.
Wang Heyong, Azul y Oro. Aplicación del método de reglas de asociación para la minería de usuarios principales de microgrupo, trabajo de inteligencia de libros, 2014, 58 (02): 115-120.
Wu Yulan, Xiao Qing. Estudio sobre la influencia de la difusión oficial de Weibo de los medios financieros - Tome el ejemplo de "S.J.Modern Communication" (Journal of China Media University), 2014, 36 (06): 53-57.
Cui Jindong, Zheng Wei, Sun Shuo. Resumen de weibo Information Communication Models and Their Evolutionary Research, Library Forum, 2018, 38 (01): 68-77.
[17] Reshef D N, Reshef Y A, Finucane H K, et al. Detecting Novel Associations in Large Data Sets[J]. Science, 2011, 334(6062): 1518-1524.
[18] Chen T , Guestrin C . XGBoost: A Scalable Tree Boosting System[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016.
Wang Heyong, Azul y Oro. Aplicación del método de reglas de asociación para la minería de usuarios principales de microgrupo, trabajo de inteligencia de libros, 2014, 58 (02): 115-120.
Cui Jindong, Zheng Wei, Sun Shuo. Resumen de weibo Information Communication Models and Their Evolutionary Research, Library Forum, 2018, 38 (01): 68-77.
[21] Katz E, Lazarsfeld P F, Roper E, et al. Personal influence : the part played by people in the flow of mass communications[J]. American Sociological Review, 1956, 17(4).
[22] Bakshy E, Hofman J M, Mason W A, et al. Everyone's an influencer: quantifying influence on twitter[C]//Proceedings of the fourth ACM international conference on Web search and data mining. ACM, 2011: 65-74.
[23] Zhang S, Xu K, Li H. Measurement and Analysis of Information Propagation in Online Social Networks Like Microblog [J][J]. Journal of Xi'an Jiaotong University, 2013, 2: 124-130.
[24] Kupavskii A, Ostroumova L, Umnov A, et al. Prediction of retweet cascade size over time[C]//Proceedings of the 21st ACM international conference on Information and knowledge management. ACM, 2012: 2335-2338.
[25] Yang J, Leskovec J. Patterns of temporal variation in online media[C]. web search and data mining, 2011: 177-186.
[26] Hu Y, Hu C, Fu S, et al. Predicting the popularity of viral topics based on time series forecasting[J]. Neurocomputing, 2016.

Se recomienda leer el libro . . .
Tourism Hot Spot: El 9o Festival de Cultura en Internet lanzó Anhua Black Tea para ayudar a sacar a la gente de la pobreza en la comida más caliente de Hunan en septiembre
"Tourist Hot Spot" la llegada del comercio electrónico de la temporada de cangrejos y luego llevar "Cangrejo del Lago Yangcheng" a septiembre la comida más caliente de Jiangsu
Análisis en profundidad: un diseño diversificado o una parte importante de la transformación del marketing
Punto caliente del turismo: La carne de res de especialidad local encabezó la lista de alimentos de Mongolia Interior en septiembre
Revisión del caso: El anciano fue tropezado y asesinado por una cuerda de perro
¿Quieres mantener un ojo en más puntos calientes e informes de datos
Síguenos

Ir a "Descubrimiento" - "Echa un vistazo" navegar "Amigos están viendo"