論文Express | タオバオ広告はどのように最適化されていますか? アリチームのリアルタイム入札システム戦略

ビッグデータダイジェスト作品
著者:小魚
タオバオの同級生は、タオバオモバイルクライアントのトップページが「あなたが好きだと思う」セクションをプルダウンし、多くの場合、あなたがタオバオで検索した関連アイテムのいくつかを推薦し、時折、誰もが小さな驚きをもたらすことを発見する必要がありますタオバオはどうやってやったの?
最近、アリのチームはarXiv.orgでリアルタイムオークション(RTB)システムのアルゴリズムに関する2つの論文を発表し、マーチャントが広告オークションで合理的な戦略を提供するだけでなく、マーチャントの利益を最大化するのに役立ちます。
ビッグ データ ダイジェストの [パブリック番号] バックグラウンド ダイアログ ボックスで返信します"スポット"2つの論文をダウンロードすることができます
ここでは、最初の論文の一部です:
マルチエキスパート強化学習に基づくリアルタイムスポットケース
ライブ広告は、広告主が各ブースの訪問者に入札するためのプラットフォームを提供します。 広告配信による収益の最大化など、特定の目標を最適化するには、広告主は広告とユーザーの関心の相関関係を推定するだけでなく、最も重要なのは、他の広告主が市場入札に戦略的に対応する必要があります。 本論文では、広告主間の取引における競争とパートナーシップのバランスをとり、実用的な分散協調マルチインテリジェンスオークションシステム(DCMAB)を提案する。 そして、アリ業界の実際のデータを使用して、モデリング方法の有効性を証明しています。
オークションの最適化は、リアルタイムオークションの最大の関心事の1つであり、広告主が各オークションのインプレッションに合理的な入札を行い、クリック数や利益などのオークションシステムの主要業績評価指標(KPI)を最大化することを目的としています。 従来のスポットアルゴリズムの欠点は、スポット最適化を静的問題として使用し、合理的なリアルタイムスポット問題を実現できないことです。
マルチエキスパート強化学習の鍵は、各エキスパートがうまく連携するメカニズムと学習アルゴリズムを設計する方法です。 タオバオには膨大な数の広告主があり、マルチインテリジェンス強化学習は、緊急の問題を解決するために使用することができます。
タオバオのディスプレイ広告システム
タオバオ広告システムでは、ほとんどの広告主は広告を掲載するだけでなく、タオバオのeコマースプラットフォームで製品を販売しています。 タオバオ広告システムは、次の図に示すように3つの部分に分かれています:最初のステップは、マッチングを行います。 ユーザの行動データをマイニングしてユーザの嗜好予測を得て,ユーザの要求を受けた場合,実際の状況に応じて,広告コーパス全体から候補広告の一部(通常は順に)をリアルタイムにマッチングする. 次に、リアルタイム予測システム(RTP)は、各推奨広告のクリック率(pCTR)とコンバージョン率(pCVR)を予測します。 最後に、候補広告のライブオークションとランキング表示が行われます。
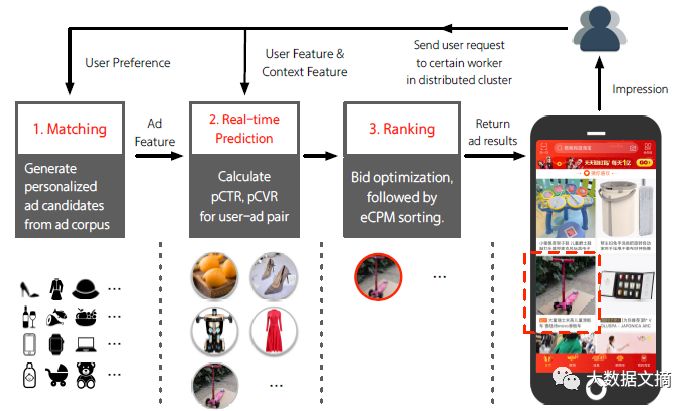
タオバオ広告システムの概要
一致、リアルタイム予測、ランク付けは、ユーザーの要求を順番に処理し、特定の数の広告を返します。これらの広告は、タオバオクライアントの「あなたが好きだと思う」セクションに表示されます。
マルチスマート広告オークションアルゴリズムの原理
リアルタイム入札はランダムゲームとも呼ばれ,Markov対策とも呼ばれる. Markov対策は、マルチステップ対策をランダムプロセスとして見、従来のMarkov意思決定プロセス(MDP)を複数の参加者の分散意思決定プロセスに拡張することです(参考文献:Li Xiaoming、Yang Yupu、Xu Xiaoming)。 MarkoV対策と強化学習に基づくマルチエキスパート協調研究[J]. 上海交通大学, 2001, 35(2):288-292).
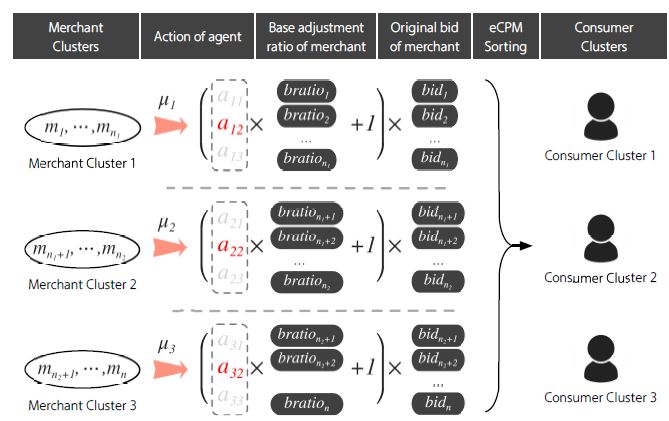
商人と消費者は、異なるクラスターに分かされています。 各マーチャント クラスターには、さまざまなコンシューマー クラスターの広告オークションを調整するエージェントがあります。 アクションの場合a_ij i はマーチャント クラスタの数を反復処理し、j はコンシューマ クラスタの数を反復します。 bratio_kは、マーチャント k の基本調整率を表します。
出力動作(スポット調整)は連続空間にあるので、論文は勾配決定性戦略を使用して入札アルゴリズムを学びます。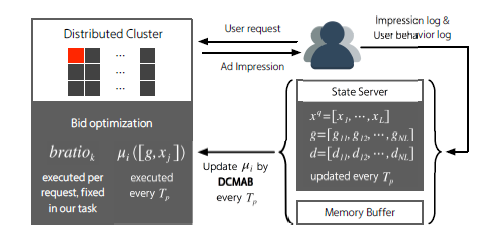
(a) タオバオ広告システムにおけるDCMABワークフロー図
状態サーバは,Agentの動作状態を維持する責任を負い,全体情報g,消費分布d,消費静的特徴x^qを含む.
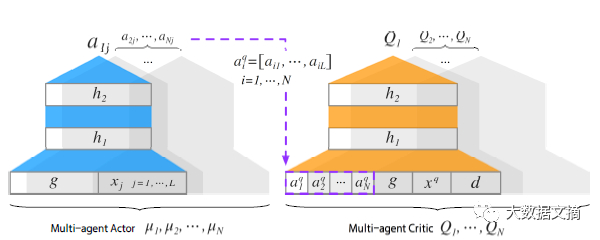
(b) DCMABネットワーク構造設計
DCMAB回路図
アルゴリズムの実装のフローチャートは次のとおりです。

実験
データセットと評価の設定
アリの業界データからのデータセットは、広告の推奨効果は、タオバオアプリのホームページ「あなたが好きなものを推測」に表示されます。
広告主の収益は、主要な評価基準です。
比較方法
入札の手動設定 (Manual)
コンテキスト スロット (Bandit)
Advantageous Actor-critic (A2C)
連続動作制御(DDPG)
分散協調マルチスマートスポットシステム(DCMAB)
実験結果
表は、異なるアルゴリズムの下で広告主が独自に入札した収益です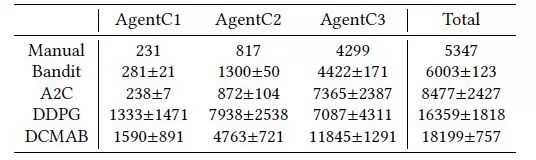
異なるアルゴリズムの収束性能を表に示します(アルゴリズムのトレーニング収束性能が後者の50データセットで変化しない場合)。 表の各行データは、対応するアルゴリズムの結果を示し、各列は、この実験で異なるエージェント クラスターの結果と広告主の総収益です。 研究者は、各アルゴリズムで4つの実験を行い、平均収入と標準偏差を与えました。
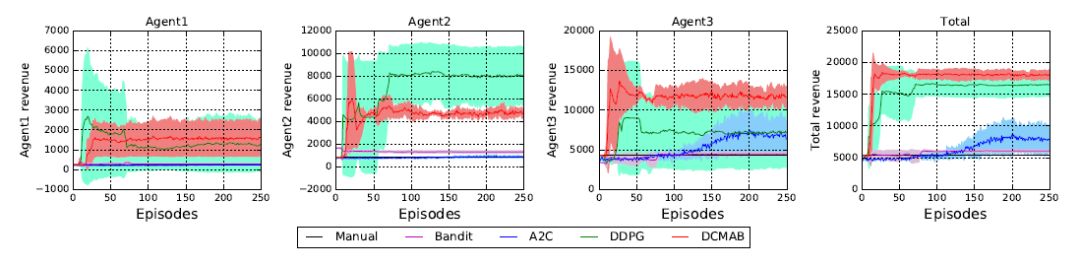 さまざまなアルゴリズムの学習曲線とベースラインの比較
さまざまなアルゴリズムの学習曲線とベースラインの比較
実験結果は、DCMABコンバージェンスがDDPGよりも安定しており、すべてのエージェントの行動を行動値関数に入力するモデリングの有効性を検証することを示している。 DCMABとDDPGはA2Cやスロットマシンよりも速く学習し,記憶回訪に基づく勾配決定性戦略の利点を示した。
第2の論文は、予算制約入札についてです, 簡単な紹介を行う, 興味のある学生は、フルテキストを読むためにダウンロードすることができます.
モデルレス強化学習に基づく予算制約入札
ライブ オークション(RTB)は、オンラインディスプレイ広告の最も重要なメカニズムであり、各ページビューの合理的な入札は、優れたマーケティング結果に重要な役割を果たします。 予算制約オークションは、RTB メカニズムの典型的なシナリオであり、広告主は限られた予算でユーザーの印象を最大化する全体的な価値を獲得します。
しかし、リアルタイム入札の最適化戦略は、取引環境の複雑さと不安定性のために達成するのが難しい場合があります。 これらの問題を解決するために、この論文では、予算制約入札をマルコフの意思決定プロセスとして扱います。 以前のモデルベースの作業とはまったく異なり、この論文では、見積もりを直接生成するのではなく、入札パラメータを順番に調整するモデルレス拡張学習に基づく新しいフレームワークを提案する。
この考え方に基づいて、深いニューラル ネットワークを展開し、適切な報酬を提供する方法を学習することで、インテリジェンスを最適な戦略に導き、探索的行動を動的に調整し、パフォーマンスをさらに向上させる適応欲張りな戦略を設計します。 実際のデータセットでテストすると、この記事で提案するフレームワークが現実的で有効であることを示しています。
上記の2つの論文の紹介は、ビッグデータダイジェストの公開番号のバックオフィスダイアログで返信する興味のある学生です"スポット"2つの論文をダウンロードすることができます
【今日の機械学習の概念】
Have a Great Definition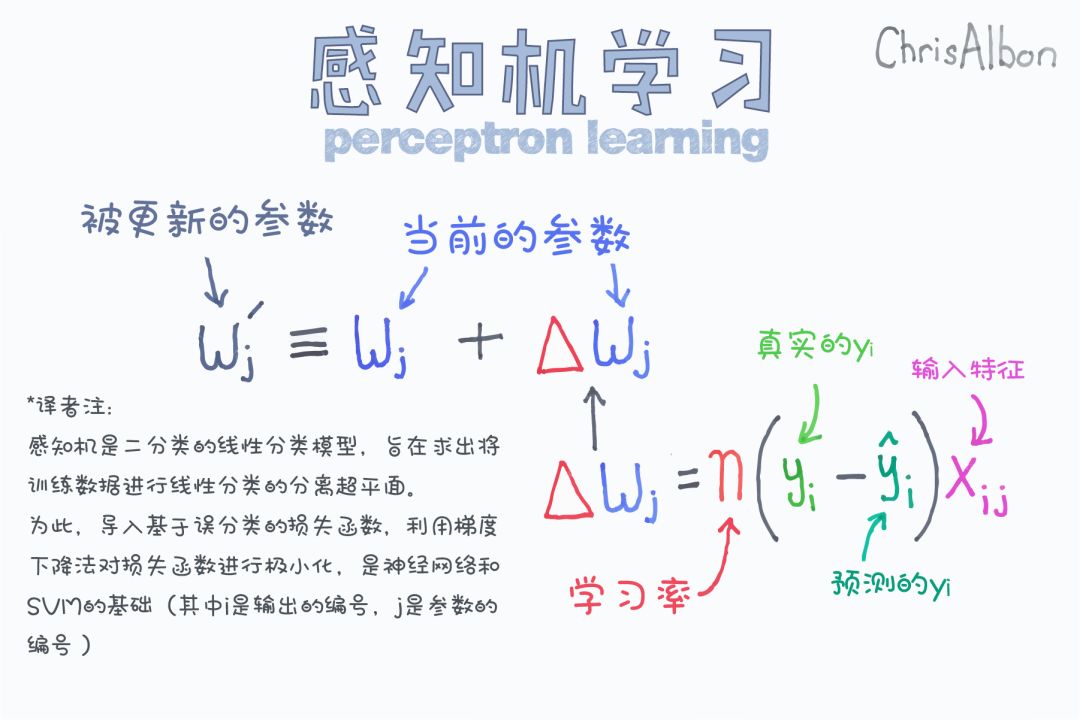
ブティックコースをお勧めします
データ サイエンス トレーニング キャンプの第 5 段階
優秀なティーチングアシスタントの推薦|ジンジャージンジャー
データ分析の理解はExcelの小さな白に限り,コードを書いてデータを分析するのは大きな問題だと考えが持たれ親しんだ. しかし、データサイエンスの実地訓練キャンプで実現しました!
手と手の教授法、ティーチングアシスタントとクラスメートの活発なコミュニケーションと議論は、私はゆっくりとコードの行はとても親切に感じさせます。 そして、コードを介して自分の頭の中でアイデアを実装し、結果を見た瞬間、それは本当にエキサイティングです!
Kaggle、天池のケースの経験の後、これらのデータコンテストにも興味を持ち始め、一緒に遊ぶことに興味を持つ小さなパートナーはありますか?
第5期北米地域ティーチングアシスタントとして、参加者の皆さん:前方高エネルギー、十分な時間を用意し、宿題を時間通りに提出できれば、修了時に生まれ変わってみてください。



「発見」-「見る」に移動し、「友人が見ている」を参照します。