テンセントのソーシャル広告はどのようにして発見されたのですか?
[フォロー] > [フィード ストリーム] をクリックします
様々な情報フロー広告、DSPプラットフォームを再生します
リアルタイムで更新します乾物を操作します
著者:チェン・ゴン、テンセントWeChat広告エンジンロジックヘッド

友人の輪の中で見たかもしれないこの声明は、BYDの自動車広告のコマーシャルです。 広告の効果は非常に良好であり、誰かが言った、それは借りていますビッグデータ商業的な誇大宣伝は、いわゆる選択は、実際には広告アルゴリズムによって選択され、WeChatは、その後、サポートの複雑なネットワークを持っているという人もいます。では、その背後にある本当の論理はどうでしょうか。
まず、システムの全体的なモジュールビューを見て、我々は4つのレベルに分かれていました。
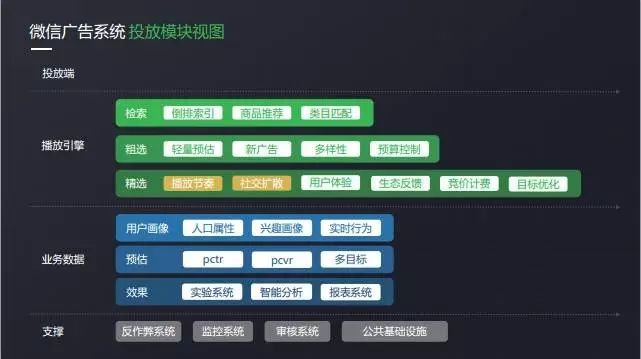
最初の層: 配信側
テンセントの広告ウェブサイトで配信できるだけでなく、パブリックプラットフォーム内でクローズドループで配信できます。
第2層:再生エンジン、ここでは、検索、大まかな選択、選択に大別されます。
1、検索:ユーザーが到着すると、年齢や性別の地域、広告配信の群衆など、独自の属性に基づいて、そのユーザーに適した広告を選択するために一致し、数千を持っている可能性があります。
2、大まかな選択:これらの100の広告をフィルタリングし、その後、選択モジュールに100を与え、ユーザーに別の選択を選択します。 粗い選択は速度に焦点を当て、効果は次に表示されます。ここでは、新しい広告のサポート、カテゴリの目的の多様性、予算の超過などの問題を考慮します。
3、最後に:選択は、より詳細に検討されます。 まず、再生のリズムコントロールであり、これは私たちの後の焦点は、広告が配信されるリズムの種類です。 第 2 に、ユーザー エクスペリエンスやエコロジーなどの問題も考慮されます。
第3層: 主にデータ関連モジュールで、詳細は後で説明します。
第4層:アンチチート、監視、監査など、サポートされているモジュールの中には、多くの企業の基本コンポーネントも使用しています。
上記はモジュールレベルから全体的に見て、以下から始めるデータ フロービューの観点から広告のビジネス シナリオ:
ビジネス データ フロー
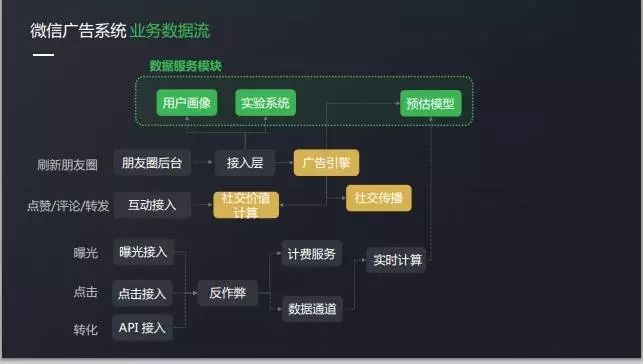
まず、ユーザーがフレンド サークルをスワイプすると、フレンド サークルのバックオフィスは、独自のアルゴリズムやその他のデータ モジュールの合成計算に基づいて適切な広告を提供する広告エンジンに要求をドロップします。
エンジン アルゴリズムでは、主にソーシャル コミュニケーション コントロール モジュールも呼び出され、広告の並べ替えの前にソーシャル コミュニケーション プロセスに基づいて群衆が動的に選択されます。
ユーザーが広告をプルすると、露出、クリック、コンバージョンなど、広告に対するさまざまな動作が行われます。
ソーシャル動作は、エンジンで使用するために計算する専用のソーシャル 拡散モジュールにも移動します。広告エンジンの位置を確認することが重要です。
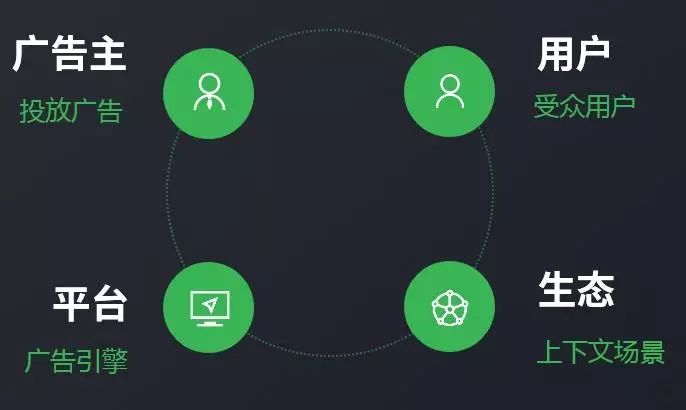
そして、WeChat広告システムの下でエンジンはどのように考慮されていますか?
広告エンジンの役割は、広告主、ユーザー、広告プラットフォーム、エコプラットフォーム間の価値利益を継続的に調整することです。
ユーザーにとって、ユーザーはエクスペリエンスを向上させ、あまりにも多くの広告を見るのを嫌がり、過度の広告ハラスメントを受け入れ、貴重な情報を期待しています。
広告主は、その効果やブランド力を高め、プラットフォームのために、それはお金を稼ぐだけでなく、口コミのバランスを取る必要があります。
そして、エコロジー側、すなわち友人サークルと公共番号は、生態学的当事者の利益を損なうわけにはいき、逆に、我々はより良い開発を促進する必要があります。
ユーザ画像システム
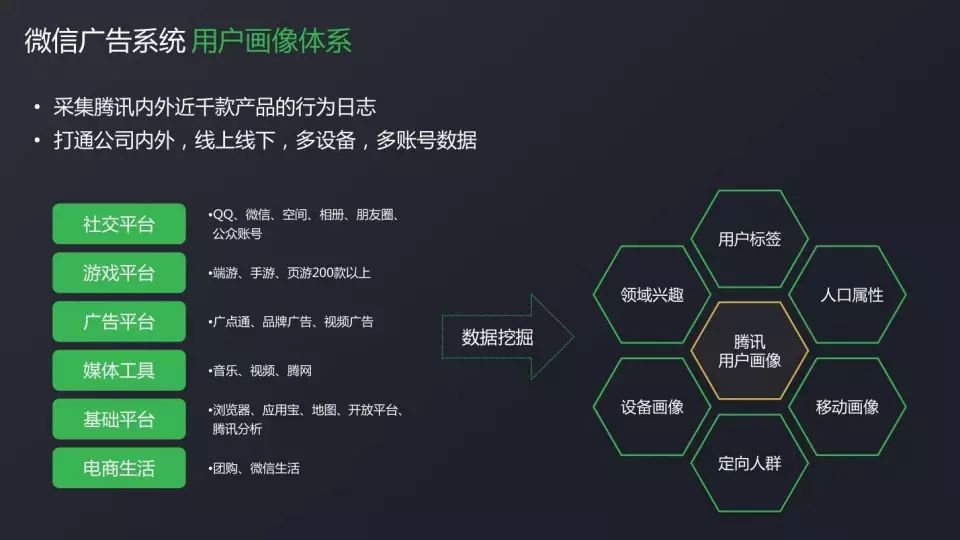
広告をうまく行うには、まず準ユーザーを識別する必要がありますユーザー ポートレートそれは私たちがそれを行うのを助ける方法です。
テンセントは、それぞれカバーする約1000の製品を持っていますソーシャルプラットフォーム,ゲームプラットフォーム,電気商プラットフォームなど、豊富な動作ログを提供します。 ユーザーの基本的な人口統計属性、趣味などを識別するのに役立ちます。
たとえば、ユーザーがパブリック番号で読む記事を使用すると、ユーザーの読書への関心を掘り起こしたり、ハイエンドかどうかなどのユーザーの個人的な状態を掘り起こしたりできます。 時間の次元を加えば ユーザーの軌跡が分かることができます 愛、結婚、子供を持つ、その後、対応するステージの広告をプッシュすることができます。
移動中インターネット時代は、我々はまた、複数のプラットフォームのデータを開き、私たちの生データを大幅に豊かにできるように、ユーザーのためのデバイス画像を作りました。
インタラクションとクリック率の見積もりモジュール
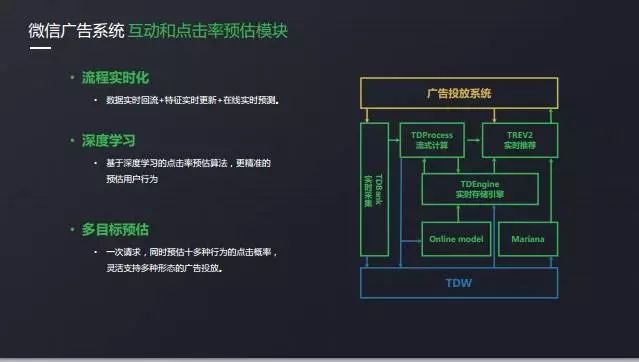 ユーザー属性を知った後、そのユーザーが何らかの行動を起こす確率、つまり広告のクリック率やコンバージョン率の見積もりについて疑問に思っているのは当然です。
ユーザー属性を知った後、そのユーザーが何らかの行動を起こす確率、つまり広告のクリック率やコンバージョン率の見積もりについて疑問に思っているのは当然です。
当社のシステムは、データ収集からモジュールのトレーニングの更新まで、プロセス全体をリアルタイムに行います。 リアルタイム化による効果の増加は10分の1です。 第二に、モデルの選択の面では、我々はまた、LRからFM、そして最後にDNNまで経験しました。
これも業界の方向性です。 最後に、私たちのマルチターゲット予測の問題は、アバターのクリック、画像のクリック、名前のクリックなど、多くの行動を持つ友人サークル広告であり、我々はアルゴリズムとシステムの両方のためのテストである10ms以内に12の行動の見積もりを完了する必要があります。
ソーシャル広告の推奨プロセス
まず、従来のパフォーマンス広告の推奨プロセスを見て、まず、ユーザーは検索システムを使用して 100 件の広告を取得します。 次に、個人の関心に基づくクリック率の見積もりに基づいて、100 件の広告のクリック確率を計算し、広告の入札単価と組み合わせ、一律に並べ替え、1 位の広告をユーザーに返します。
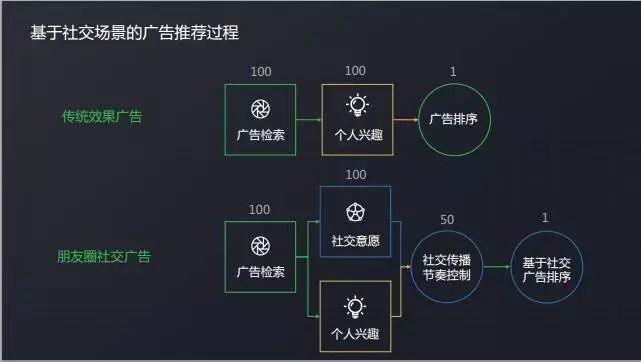 そして、友人のサークルのソーシャル広告では、まず、もちろん、検索を通過します。 そして、ここでは、ユーザーのクリックの関心に基づいて推奨されなくなったが、また、この広告に対するユーザーの社会的意欲も考慮する必要があります。
そして、友人のサークルのソーシャル広告では、まず、もちろん、検索を通過します。 そして、ここでは、ユーザーのクリックの関心に基づいて推奨されなくなったが、また、この広告に対するユーザーの社会的意欲も考慮する必要があります。
ソートする前に、ソーシャルコミュニケーションの配信リズムコントロールも通過します。 各広告が現在どのユーザーに適しているかを確認し、ユーザーをフィルタリングします。 最後に、ソーシャル要因を考慮した広告の並べ替えの後、ユーザーに広告を返します。
次に、これらの 3 つのプロセスを具体的に見てみましょう
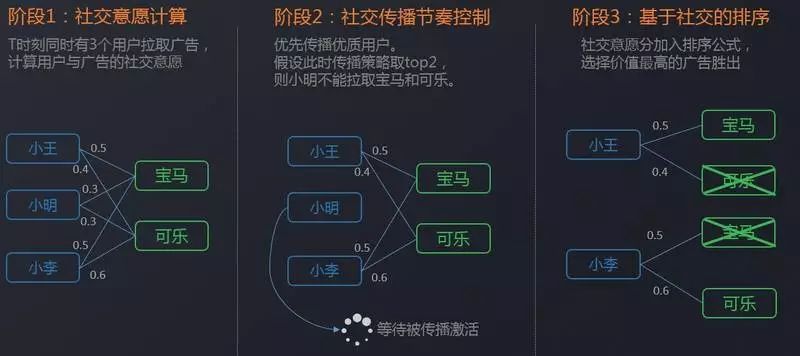
社会的意志、社会的コミュニケーションのリズムコントロール、ソーシャル広告に基づくソートソーシャル広告配信の三部作です。
第一段階、社会的意志の計算段階は、現時点では3人のユーザーが同時に友人の円を訪問し、BMWを持っていると仮定しますコカコーラ2つの広告オンライン、3人のユーザーは、これらの2つの広告に2つの社会的相互作用を望む。
第2段階、社会的コミュニケーションリズムコントロールは、広告選択段階であり、この瞬間は、3人のうちの2人が広告を受け取るために最善である場合、スコアに基づいて、Xiaomingは、この瞬間にBMWとコーラの2つの広告を受け取る方法がない見つける。 しかし、これは単に、この瞬間、広がりが広がり、Xiao Mingがますます多くの友人の影響を受け、彼は次の瞬間に広告を受け続ける可能性が高いという意味です。
第3段階、ソーシャル ベースの並べ替えステージ。 この時点で、ユーザーは受け取る広告のリストを取得し、並べ替え式にソーシャル意欲を追加し、ユーザーに最適な広告を選択します。
社会的意志の計算
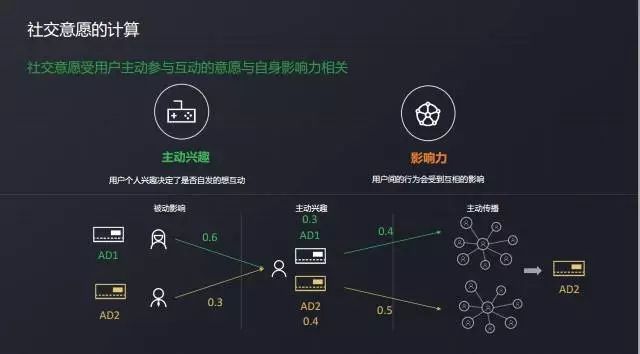
ユーザーの社会的意志は、個人的なイニシアチブのインタラクティブな関心に加えて、友人によって影響されます。 上の図の影響のいくつかの段階を見てください。
真ん中、ユーザーは、他の人の影響を受けない2つの広告に積極的な関心を持っています。
左2 人のフレンドが 2 つの広告をやり取りし、そのユーザーの影響とは異なります。
右側ですは、広告を受け取った後、私の相互作用が他の人に与える影響を示す普及プロセスです。
友人の輪の中での影響力とブランド力知覚の関係を例にとります。
シャンプーの広告を見た場合、それはスーパーマーケットの一般的なブランドである可能性があり、それを使用していないか、あまり注意を払わないです。 しかし、この時点では、すでに多くのあなたの友人は、以下のコメントをいいね、反応の切りくずは本当に素晴らしいです。
この時点で、あなたは私のシャンプーがフケを持っているように見えると思うかもしれないので、これを試してみてくださいか? この時点で、あなたは友人に「私もそれを試してみてください」と返信することができますが、あなたは答えではないかもしれませんが、この時点では、ブランドの印象は深まる必要があります。
そして、これらの議論の友人の1人を考えると、あなたの上司の1人が、おそらく通常、あなたが話す機会を持っていない場合、この時間は、承認を表明するために賞賛を与える必要がありますか? また、注目を集める可能性があります。
これは社会的影響の役割であり、ここでの主な問題は、その影響を定量化する方法です。
第1に、友人間の影響評価は、親しい2人の友人ほど影響力が大きいため、通常、親密さに基づいてモデルが構築される。 しかし、限られたシステムを通じて、我々は、それが少し利益をもたらすことを発見し、さらにデータ分析主な原因は、目標の不整合です。
例えば、私たちは両親と特に親密ですが、友達の輪に投稿された内容についてコメントしません。 そこで,AがBの日常的なインタラクションに影響を与える確率を,より関連のある行動によって影響を評価し,インパクトと定義するが,このデータは一定の信頼度では疎であるため,モデル推定により計算する.
ここでは、基本的な機能の一部に加えて、いくつかのネットワーク機能を使用します。
たとえば、フレンド ネットワークでは、通常、WeChat ユーザーは 8 億人であり、これは 8 億 *8 億の隣接行列です。 これはモデルトレーニングのfeatureとしては使いにくい.
同時に、メッセージの相互作用、記事の読み取りなど、他のネットワークがあります。 さて、ここでは、呼び出しの種類を採用しています node2vecメソッドは、これらのグラフ ノードを 1 つのベクトルにマップします。 このベクトル次元は比較的低く、トレーニングのためにこれを使用することができます。
最終的には、GBDT と LR を使用して影響の見積もりを行います。
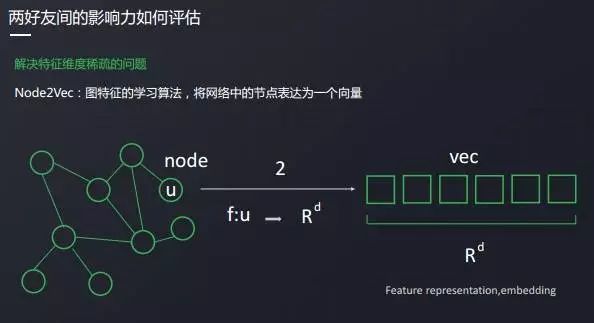
Node2vec は embedding の一種です。
まず、図のノード情報を使用して、元のネットワーク情報をできるだけ多く保持する方法です。 に変更します自然言語処理一般的な単語は、その周りの単語で表現することができます,これはword2vecの考えです。
この図では、ノードの周囲のノードで表します。node2vecサンプリング方法の問題を解決することです。
次に,サンプリングしたベクトルをword2vecの方法で訓練し,各ネットワークノードが表現できるベクトルを得る.

私たちはすでに2人の友人が自分自身に与える影響を知っていますが、非常に多くの友人は、どのようにお互いに影響しますか? ここでは、この問題をモデル化するために伝播力モデルを導入します。
従来の影響モデルにはさまざまな種類がありますが、ここでは最も一般的な独立性を示しますカスケード モデル。 その原理は、ユーザーのすべての友人が自分自身に影響を与え、その影響は、前に述べた方法で計算することができるという考えです。
初期の瞬間には、すでにいくつかの人々がアクティブにされ、これらの人々はシードユーザーであり、私は後で言う特定の選択を持っています。 その後、ユーザーのアクティブ化された各フレンドは、以前の影響に基づいてアクティブ化確率を計算し、ユーザーを順番にアクティブ化します。 これにより、各ラウンドでユーザーの場所が新しくアクティブ化されるまで、サブイテレーションが続きます。
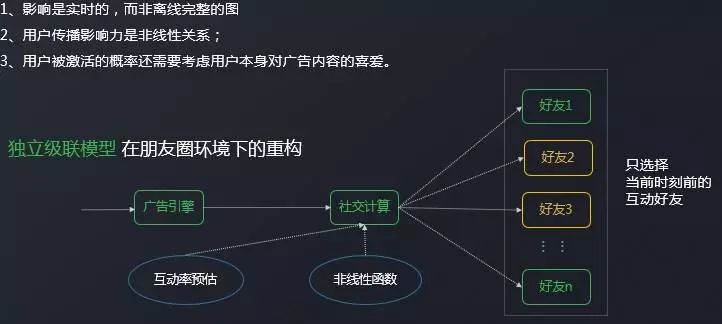
伝統的な独立カスケード モデル直接アプリケーションには図に示されている問題がいくつかあるため、上の図の下の形式 (図) に変更しますが、これを行うにはエンジニアリング上の問題があります。
主に広告システムのレイグ要件は非常に低く、ユーザーが数百台のストレージマシンに分散した5,000人の友人を持っている場合、20msで読み終えるのはほとんど不可能です。
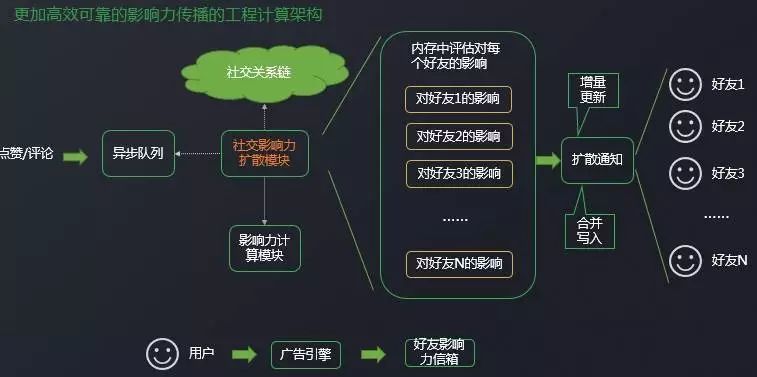
その後、拡散を読むこの方法は、我々は別の思考を取り、拡散を書く方法を採用します。 ユーザーのいいねコメント データが受信されると、メッセージ キューに入れ、ソーシャル 拡散モジュールが取り出され、リレーションシップ チェーン、権限、および伝播力に基づいて取得されますメモリから各フレンドへの影響を計算し、その後、すべてのフレンドにこのメッセージを通知します。
しかし、5,000 人の友人が 5,000 件の Web 呼び出しを行う必要がある場合、このオーバーヘッドは許容されません。 したがって、ルーティング ルールとマシン リストに基づいて、1 台のマシンに属するユーザーをマージして書き込みを行い、ネットワーク呼び出しを最小限に抑えます。
これを行った後、ユーザーが広告をプルすると、Web 呼び出しが 1 回だけ必要で、友人が彼に与える影響を取得できます。
注: 現在、より多くの機能をリアルタイムで推奨するために、上記のスキーマをグラフィックス ベースに変更しましたデータベースアーキテクチャは、より複雑で巧妙であり、その後、記事で紹介されます。
ソーシャルコミュニケーションリズムコントロール
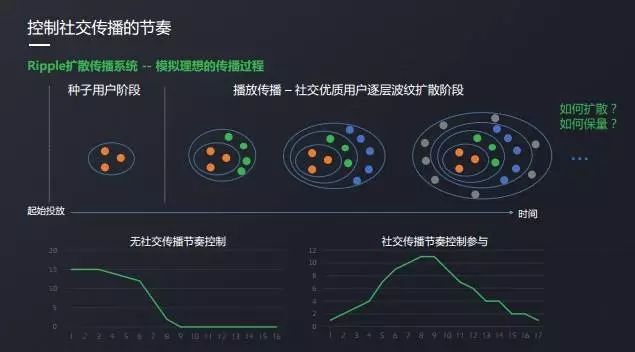
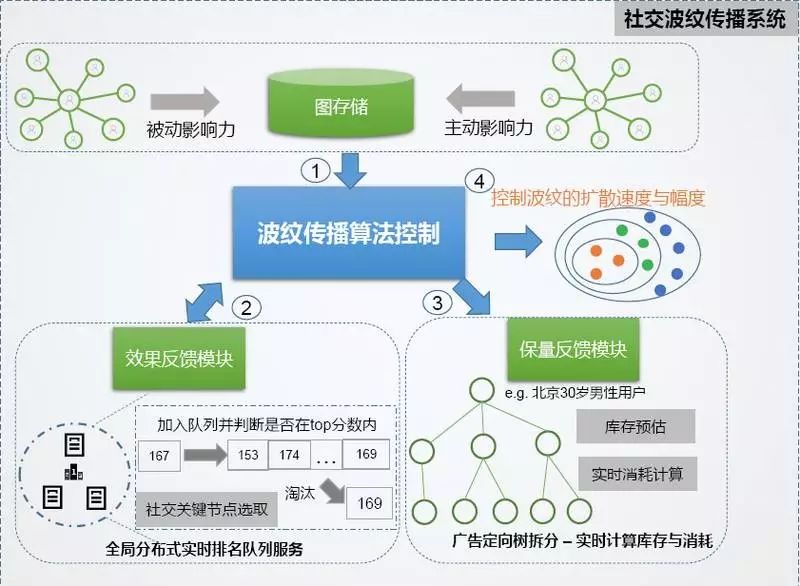
ソーシャルコミュニケーションリズムコントロールの核となる考え方は、まず質の高い人々に広め、その後、質の高い人々が他の人を牽引できるようにすることです。 次の図に示すように、Ripple 拡散伝播システム。
プレミアム集団とは,投入初期にシードユーザと定義される.
彼らはいくつかの方法で掘る:
まず第一に、広告主のファン、ハードコアファンユーザー。
第二に、広告主は、自分のユーザーを最もよく知っているので、広告主のニーズに応じて、ターゲットをターゲットとし、ユーザーを行動します。
ご存知のように、InfoQ のファン層は膨大で、ファンや業界の影響力のあるグループを選択して、高品質のユーザーを特定しました。
同時に、大きなスケールが十分でないと感じた場合は、lookalike メソッドを使用してユーザーを拡張し、前の 2 つの手順と同様のユーザーを大きなディスクに見つけることができます。
では、質の高い人口はどのように決定されるのでしょうか。 グローバルなリアルタイムランキングキューを導入することで、各ユーザーと各広告のリアルタイムソーシャル価値を分析し、異なる期間に質の高い群衆を定義する関数が異なります。
プレミアムユーザーを選択すると、当社のripple拡散拡散システムに拡散し、シードユーザー段階から配信され、広告予算の終わりまで徐々に拡張されます。 プロセスは単純に見えますが、実際の配信はより複雑なプロセスです。
まず第一に、影響リアルタイムで動的に変化するプロセスであり、第二に、友達の輪の広告に基づいていますユーザーのプル単純なプッシュではなく、拡散を理想化できません。
この2つの背景の後、拡散の比例値をどのように決定するかなど、拡散の具体的な方法の問題に直面し、また、一般的なブランド広告主は、システムのリアルタイム性とアルゴリズムの両方に高い要件を持つ、ボリューム要件の下で社会的拡散アクションを完了するための契約保証を必要とします。 次の図は、リップル伝播システムのいくつかのコンポーネントを示しています。
ソーシャル ベースの並べ替え
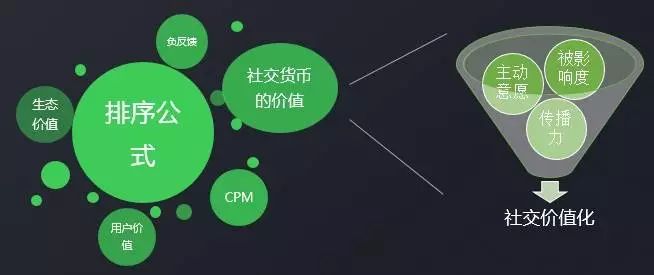
他の人の注意、コメント、いいねと引き換えに、それは呼び出すことができますソーシャル通貨。
システム内で導入された変数は、それを価値化し、収益化します。収益化された値を合計値の並べ替えに配置し、広告主の初期価格と広告主の情報を並べ替えると、広告の価値の拡大は、ソーシャル コミュニケーションに対する当社の重点を表します。
多くのことは、あなたが思うほど簡単ではありません
もちろん、あなたが思うほど難しくありません


私に従ってください、あなたのターンを再生する方法を教える
情報フロー広告
ドライ商品の運用をリアルタイムで更新します

「発見」-「見る」に移動し、「友人が見ている」を参照します。