No se puede perder el concurso de algoritmos universitarios de publicidad social de Tencent: el primer video en vivo del juego y la colección de respuestas de expertos

Ayer, Tencent publicidad social universidad algoritmo concurso preliminar pregunta-y-respuesta expertos transmitidos en vivo, recibió mucha atención
Ya sea en el lugar o en línea, los pequeños socios son preguntas muy activas y entusiastas
Nuestros expertos también son pacientes y meticulosos uno por uno para responder
Muchos estudiantes están preguntando sobre el sitio web de la grabación
Vamos a repasar juntos la transmisión en vivo de ayer

El experto respondió a la pregunta

El pequeño editor íntimo será la sesión de respuesta experta de ayer de las preguntas frecuentes se han grabado
Los estudiantes no tienen que tomar notas
1. ¿Es yi los datos que necesita predecir, necesita rellenar la prueba, cómo conoce la función de evaluación mi yi, es la tasa de conversión 0 reconocer mi yi como 0?
yi es la etiqueta de los datos de prueba y no se proporciona. Al enviar una estimación, cada línea es necesaria para dar un instanceID y una probabilidad estimada, y logloss se calcula comparando el instanceID con las respuestas estándar en segundo plano.Se puede hacer referencia al método de cálculo https://www.kaggle.com/wiki/LogLoss
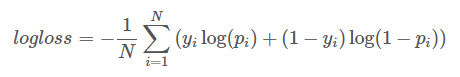
2. Pregunta: ¿Cuál es la identidad de los usuarios 2g, 3g, 4gwifi? Muchos campos, aunque son más o menos significados, no dan un número correspondiente específico.
Por razones de seguridad de datos, todas las características se cifran y no proporcionan correspondencia de identificación, lo que no afecta a la creación de problemas normales.
3. ¿Puede explicar en detalle lo que significa el appID, y la correspondencia entre la categoría de la aplicación y el appID?
Un appID es un número cifrado para una aplicación específica. Una aplicación/appID corresponde a su categoría de clasificación, como se detalla en el archivo app_categories.csv.
4. ¿Cómo tratar con una cantidad tan grande de datos en caso de una máquina independiente deficiente?
¿La configuración de la máquina es demasiado baja? Encontrar una mejor máquina, de acuerdo con nuestra autoprueba, configuración de la máquina: memoria 16G, CPU 8 núcleo, debe ser suficiente, especialmente el volumen de datos inicial no es grande, para no ser un problema. De antemano, también proporcionaremos algunas máquinas en la nube Tencent para los estudiantes que necesiten elegir durante la remate.Además, también puede comenzar desde el punto de vista de los modelos de representación de entidades y algorítmicos, comprobar si es necesario optimizarlo, por ejemplo, puede realizar la selección de entidades o cambiar para lograr mejores herramientas.
5. ¿Qué pasa con las variables de propiedad multivalor? ¿Como este creativo?
Las variables de categoría de varios valores se encuentran en casi todas las tareas pCTR/pCVR, como los ID de tráfico, los ID de bits de anuncio, etc. La forma habitual de manejar esto es codificarlo de un solo calor. Por ejemplo, el valor sexual de hombre, mujer, desconocido, se puede codificar como . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . Otros tratamientos se mencionarán más adelante en nuestro artículo de línea de base.
6. ¿Cuál es la mejor solución para muestras positivas y negativas cuando son muy diferentes, y cuál es la idea general para la combinación de múltiples características?
En el problema del desensuización, los casos negativos con un tamaño de muestra grande generalmente se pueden reducir (manteniendo el caso positivo intacto) para acelerar el entrenamiento del modelo. Además, para mejorar el efecto, se pueden utilizar diferentes semillas aleatorias para muestrear, entrenar el mismo modelo y, a continuación, integrar el modelo. Puedes consultar el estilo de modelado de Owenzhang en el juego Avito Click Rate Estimation 2. En particular, cabe señalar que el indicador de evaluación de este concurso es logloss, que es sensible a la distribución de la proporción positiva y negativa de la muestra, después del muestreo, cambiando la distribución original de la muestra, generalmente es necesario escalar los resultados de predicción, de modo que esté cerca de la distribución de los datos originales.
En cuanto a la combinación de características, se requiere un análisis específico de cuestiones específicas. Si se trata de una función de identificación, simplemente puede hacer cruces de productos Descartes. En el caso de entidades numéricas, como ciertas estadísticas, puede multiplicar y dividir transformaciones, etc. Además, se recomienda probar modelos como XGBoost y DNN, donde puede aprender mejores combinaciones de características de sus datos.
7. Lo que me gustaría preguntar al experto es que el sobreadaptamiento xgboost es muy serio, hay parámetros que controlan el sobrefit, pero no parece funcionar, ¿es la característica necesidad de hacer algún procesamiento?
El sobrefit aquí puede ser en dos casos. Uno, la insistencia entre el efecto offline y el efecto en línea. Dado que los datos son datos de series temporales, la distribución varía con el tiempo y es comprensible que haya una brecha entre el efecto sin conexión y el efecto en línea. Si la tendencia de cambio entre los dos es muy consistente, por ejemplo, hay una mejora fuera de línea, también hay una mejora en la línea, creo que esta es una mejor verificación local. Si las dos tendencias no están de acuerdo, deberá comprobar si el conjunto de entrenamiento local y el conjunto de validación se han creado correctamente, por ejemplo, debido a la división aleatoria. La otra es la insistencia entre el conjunto de entrenamiento local y el efecto del conjunto de validación. Creo que esto es normal, el valor del parámetro de ajuste excesivo de control también debe basarse en el efecto anterior al conjunto de validación para asegurarse de que el modelo en el efecto del conjunto de pruebas. También se mencionan características, porque son datos de series temporales, extracción de características anteriores realmente necesitan ser más cuidadosos, para evitar la aparición de fugas de datos, para evitar esta causa de sobreajuste.
8. ¿Ordenar el proceso de negocio publicitario?
El sitio web de publicidad social de Tencent tiene un centro de aprendizaje(http://e.qq.com/ads/learning), proporcionar un gran número de materiales relacionados con el negocio publicitario para que todo el mundo los entienda.
En pocas palabras, Tencent Social Ads es un sistema de publicidad dirigido por el usuario que permite a los anunciantes dirigir anuncios a los usuarios que cumplen ciertos criterios, como las etiquetas enriquecidas dirigidas por el usuario que ofrecemos.
Los anunciantes deben crear materiales creativos, seleccionar el espacio publicitario para publicar, rodear las personas y el período de tiempo para publicar, establecer pujas y el presupuesto total, a través de la revisión, puede mostrar anuncios en un período de tiempo preestablecido.
Dado que las plataformas publicitarias son fáciles de obtener exposición de anuncios, registros de clics y los anunciantes están más preocupados por las conversiones, como el comportamiento de activación de aplicaciones en esta pregunta, animamos a los anunciantes a volver a devolver los registros de conversiones a través de nuestro SDK o API, lo que ha demostrado que agregar factores de conversión al modelo de clasificación puede aumentar significativamente el ROI del ANUNCIANTE.
9. Problemas de tiempo de contraflujo en Train, un gran número de usuarios en pocos minutos para lograr múltiples clics consecutivos y conversiones es lo que la situación, hay varios registros consecutivos, pero sólo la primera conversión después de ninguna conversión, esto en una escena específica es lo que es. ¿Hay un caso de una activación, varios registros?
Este será sin duda el caso, pero la cantidad no es grande. Si es un anuncio diferente, todo va a estar bien. Si el mismo anuncio se convierte después de varios clics consecutivos, solo asociamos la conversión con el último clic y, a continuación, destacamos que esta situación será muy rara.
10. En la sección de limpieza de datos, no hay nada clásico sobre los problemas CTR que sean mejores para este conjunto de datos
Las competiciones CTR generalmente proporcionan múltiples archivos, datos dispersos alrededor, la operación más común es combinar cada dato. En esta competencia, los múltiples campos de datos proporcionados son básicamente en forma de identificaciones, generalmente un-hot en él, sin la necesidad de limpieza adicional. El desafío son los datos de la aplicación, el número de aplicaciones instaladas por cada usuario es diferente, y cómo convertir a características también es un desafío. Puede consultar el juego TalkingData por encima de Kaggle.
11. Parte de ingeniería de características, una característica común de los problemas CTR.
ID características cruzadas, características estadísticas de ID, etc., comúnmente disponibles en la referencia Kaggle antes de Criteo, Avazu, estimaciones de tasa de clics de Avito para escenarios de código abierto para el juego.
12. ¿Qué significa la APP aquí, es software móvil, o aplicaciones web, o lo que se incluye?
Puede ver el título, la estimación de la tasa de conversión de anuncios de la aplicación móvil, es decir, el software en el teléfono inteligente.
13. Cuando se enfrenta a un cuello de botella de puntuación, ¿hay alguna otra forma de pensar que mejore significativamente?
La integración del modelo puede dar lugar a mejoras significativas en la mayoría de los casos. Sin embargo, se recomienda dedicar más tiempo al análisis de datos y a la ingeniería de características, una buena característica, no sólo mejorará el efecto de un solo modelo, sino que también la integración del modelo tendrá una mejora mayor. Además, la combinación de características y el ajuste de parámetros adecuados también pueden mejorar el efecto del modelo hasta cierto punto.
14. Todos dijeron que la FFM es actualmente la mejor manera de hacer estimación de la tasa de conversión de publicidad, pero el uso real del efecto no es bueno xgboost, ¿quiere preguntar cuáles son las ventajas de los dos?
FM/FFM es mejor para las características de un gran número de clases de ID dispersas, pero puede depender más de la ingeniería de características (la forma de tejido de la característica de muestra); XGBoost está casi fuera de serie y se ejecuta más rápido. FFM y XGBoost tienen diferentes efectos en escenarios específicos, relacionados con tareas, datos, características y cómo se utilizan, y no he visto cuál es absolutamente universal. En las competiciones de estimación de tasas click-through de criteo y Avazu, las pocas son casi siempre FFM, pero en la posterior competencia de pronóstico de tasa de clics de Avito, la experiencia del ganador Owenzhang es que "XGBoost es mucho mejor que FFM".
15. Siento que este juego antes de un período de tiempo está en el ajuste de los parámetros, hasta que no mucho tiempo en el comienzo para hacer la minería de características, y la limpieza de datos, ahora difícil es la minería de características ah, como una novle, acaba de comenzar con el GBDT tradicional para hacer características, pero el efecto es general, es ahora su propio negocio de análisis estadístico, espero que la conferencia experta puede decir cómo hacer análisis de datos, permítanme tomar menos desvíos.
El análisis de datos, la ingeniería de características, etc. son más como un arte, relacionados con la experiencia. Se sugiere hacer algunas ideas, referencias y referencias a algunos esquemas existentes.
16. ¿Puedo preguntar a los usuarios userID son categorías, además, después de que el efecto de clasificación es mejor, hice un pequeño efecto de agrupación de usuarios de aplicaciones basada en la historia no parece significativo, hay una mejor manera?
En primer lugar, el ID de usuario es la identidad única del usuario después del cifrado, no una categoría. Diferentes usuarios tienen características de comportamiento diferentes, por lo que debe haber algún valor. En cuanto a si podemos hacer la agrupación en clústeres de usuarios primero, podemos probarlo nosotros mismos.
17. ¿Significa que no necesito hacer una instantánea después de haber hecho una instantánea en algunas categorías, y la promoción es muy pequeña, menos de 1 mil puntos?
El modelo utilizado por los concursantes no está claro aquí. Si LR/DNN, uno-hot es razonable. Si utiliza modelos de árbol como RF/XGBoost, puede utilizar One-hot para que estas entidades de categoría se dividan como entidades numéricas y, a continuación, se dividan. Especialmente si las entidades de categoría tienen más valores, como 100W, puede introducir XGBoost directamente. Por supuesto, hay otras maneras de diseñar mejores características.
18. Hice algunas tasas de conversión, y las características de conteo eran casi ineficaces. ¿Puedes dar una pequeña idea de la extracción de características?
La tasa de conversión y las entidades de recuento ya son características relativamente comunes, el efecto no es obvio, puede comprobar si hay un problema cuando se extrae la característica. Dado que la muestra son datos de series temporales con información de tiempo, el factor de tiempo también debe tenerse en cuenta en la extracción de entidades para evitar la fuga de datos. Además, la experiencia con la extracción de características se puede encontrar en Criteo, Avazu, y el concurso de estimación de tasas click-through de Avito, que tiene una amplia variedad de características.
19. Sólo quiero saber cómo representar la relación entre las características, como algunos usuarios a menudo descargan aplicaciones, cómo extraer de acuerdo con user_installedapps.csv?
Una forma es usar la lista de instalación de la aplicación del usuario o el flujo de instalación como un documento, y la aplicación como Word, utilizando Bag of Words para construir características. Como alternativa, puede contar la lista de instalación de la aplicación del usuario o el flujo de instalación, utilizando algunas estadísticas como una característica.
20. Para el escala de tiempo que se da en esta competencia no podemos establecer efectivamente conjuntos de verificación fuera de línea, pregunte a los expertos ¿qué piensan?
Los datos proporcionados por esta competencia son los datos de series temporales, que generalmente se dividen en conjuntos de entrenamiento local y conjuntos de validación por tiempo. Una de las dificultades de este problema es que los datos en los últimos días de la etiqueta de datos de entrenamiento s 0 pueden ser ruidosos debido al retraso en el flujo, en cuyo caso cómo construir un conjunto de validación eficaz es también un desafío para los jugadores a considerar.
Una sugerencia, los datos proporcionan un tiempo de devolución, puede ser un día, dos días pueden fluir la cantidad de datos. Esto le permite analizar las diferencias entre los conjuntos de validación que construye y los datos reales. Otro consejo es que los datos de conversión son proporcionados por los anunciantes y es una pista.
21. El muestreo aleatorio se refiere a train.csv, test.csv, ¿verdad? ¿Están completos los otros 6 archivos?
Así es. Los otros seis archivos son todos los datos sobre los usuarios, anuncios y bits de anuncio involucrados en el conjunto de entrenamiento y conjunto de pruebas, que se pueden considerar completos dentro del ámbito de la pregunta.
22. Train.csv tiene una muestra duplicada, ¿cómo entiende esta muestra duplicada? ¿Cómo se generan los datos duplicados y se pueden eliminar directamente?
Todas las muestras son datos de comportamiento reales, no artificiales, y es normal tener muestras duplicadas que deberían ser valiosas.


Terminar.
Para obtener más información, visite el sitio web oficial del evento en http://algo.tpai.qq.com
Canales de participación en concursos: http://algo.tpai.qq.com/person/mobile/index
Por supuesto, hay:
El concurso oficial WeChat del algoritmo para dar regalos cuando no encaja: TSA-Contest
Zapatos de niños que tienen miedo de demasiados regalos, por favor presten atención a ellos


Haga clic para leer el artículo completo y ver el video en vivo
Ir a "Descubrimiento" - "Echa un vistazo" navegar "Amigos están viendo"