NoSQL y escenarios principales
En comparación con las bases de datos de relaciones tradicionales, NoSQL tiene clasificaciones más complejas: valores clave, datos de datos orientados a documentos, almacenamiento de columnas y gráficos. Aquí hay un vistazo a los diversos tipos de escenarios NoSQL y opciones para algunas empresas conocidas.
En los últimos años, las bases de datos de relaciones han sido la única opción para la persistencia de datos, y los trabajadores de datos han considerado filtrar solo en bases de datos tradicionales como SQL Server, Oracle o MySQL. Incluso tomar algunas decisiones predeterminadas, como el uso. NET generalmente elige SQL Server; Java puede favorecer a Oracle, Ruby es MySQL, Python es PostgreSQL o MySQL, y así sucesivamente.
La razón es simple: la robustez de la base de datos de relaciones se ha demostrado en la mayoría de las aplicaciones durante mucho tiempo. Podemos usar estas bases de datos tradicionales para controlar las mismas operaciones, transacciones, etc. Pero si las bases de datos de relaciones tradicionales han sido tan confiables, ¿qué más es NoSQL? NoSQL sobrevive y se desarrolla porque hace lo que las bases de datos de relaciones tradicionales no pueden!
Problemas en la base de datos de relaciones
Impedance Mismatch
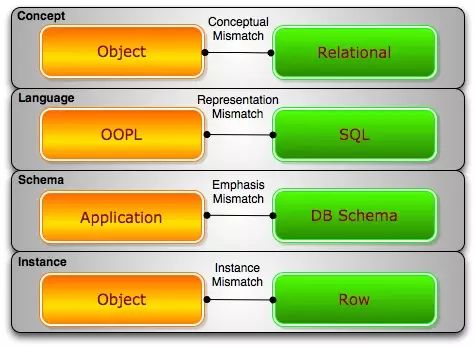
Usamos Python, Ruby, Java, . Escribir aplicaciones en lenguajes como Net, que tienen una característica común, orientada a objetos. Pero usamos MySQL, PostgreSQL, Oracle y SQL Server, y estas bases de datos también tienen una característica común: la base de datos de relaciones. El término "Impedance Mismatch" está implicado aquí: la estructura de almacenamiento está orientada a objetos, pero la base de datos está relacionada, por lo que necesitamos realizar transformaciones cada vez que almacenamos o consultamos datos. Los marcos ORM como Hibernate y Enterprise Framework simplifican el proceso, pero se estiran cuando hay una necesidad de alto rendimiento para las consultas.
El tamaño de la aplicación crece
A medida que las aplicaciones web crecen en tamaño, necesitamos almacenar más datos, servir a más usuarios y exigir más potencia informática. Para hacer frente a esta situación, tenemos que seguir expandiéndonos. Las extensiones se dividen en dos categorías: expansión vertical, es decir, comprar mejores máquinas, más discos, más memoria, etc.;
A gran escala, la expansión vertical no juega un papel importante. En primer lugar, una sola mejora del rendimiento de la máquina requiere una enorme sobrecarga y un límite de rendimiento, y en una escala como Google y Facebook, nunca es posible utilizar una sola máquina para soportar toda la carga. En vista de esta situación, necesitamos una nueva base de datos, porque la base de datos de relaciones no se ejecuta bien en el clúster. Sí, es posible que desee crear una red de bases de datos de relaciones, pero están utilizando el almacenamiento compartido, que no es el tipo que queremos. Luego está la era NoSQL, liderada por Google, Facebook y Amazon, que están tratando de manejar más transmisiones.
Era NoSQL
Ya hay muchas bases de datos NoSQL, como MongoDB, Redis, Riak, HBase, Cassandra, etc. Cada uno tiene una de varias características:
Ya no usan lenguajes SQL, como MongoDB y Cassandra, que tienen sus propios lenguajes de consulta
Esto suele ser un proyecto de código abierto
Nacido para ejecutar el clúster
Débilmente estructurado - no hay restricciones estrictas en los tipos de estructura de datos
El tipo de base de datos NoSQL
NoSQL se puede dividir ampliamente en cuatro categorías: Key-value, Document-Director, Column-Family Databases y Graph-Director Databases. He aquí un vistazo a este tipo de características.
Base de datos key-Value
Una base de datos de clave-valor es como una tabla hash utilizada en un lenguaje tradicional. Puede agregar, consultar o eliminar datos con claves y obtener un buen rendimiento y escalabilidad porque usa el acceso a claves principales.
产品:El Dynamo-Project Voldemort de Riak-Redis-Memcached-Amazon
有谁在使用:GitHub (Riak)-BestBuy (Riak)-Twitter (Redis和Memcached)-StackOverFlow (Redis)-Instagram (Redis)-Youtube (Memcached)-Wikipedia (Memcached)
El escenario aplicable
Almacene información de usuario, como sesiones, perfiles, parámetros, carros de la compra y mucho más. Esta información está generalmente vinculada al identificador (clave), que es una buena opción para una base de datos de valores de clave en este escenario.
La escena no se aplica
1. En lugar de consultar por clave, consulte por valor. No hay ninguna manera de consultar valores en la base de datos Key-Value en absoluto.
Relaciones entre los datos que deben almacenarse. Los datos no se pueden asociar a dos o más claves en la base de datos Key-Value.
Soporte para transacciones. No es posible revertir cuando se produce un error en la base de datos Key-Value.
En segundo lugar, para la base de datos orientada a documentos
Una base de datos orientada a documentos almacena los datos como un documento. Cada documento es una unidad de datos independiente, una colección de elementos de datos. Cada elemento de datos tiene un nombre y un valor correspondiente, que puede ser simplemente un tipo de datos, como cadenas, números, fechas o tipos complejos, como listas ordenadas y objetos asociados. La unidad más pequeña de almacenamiento de datos es un documento, las propiedades del documento almacenadas en la misma tabla pueden ser diferentes y los datos se pueden almacenar en muchas formas, como XML, JSON o JSONB.
产品:MongoDB-CouchDB-RavenDB
有谁在使用:SAP (MongoDB)-Codecademy (MongoDB)-Foursquare (MongoDB)-NBC News (RavenDB)
El escenario aplicable
1. Registros. En un entorno empresarial, cada aplicación tiene información de registro diferente. La base de datos Document-Design no tiene un patrón fijo, por lo que podemos usarlo para almacenar información diferente.
Análisis. Dada su débil estructura de patrón, se pueden almacenar diferentes métodos de medición y agregar nuevas medidas sin cambiar el patrón.
La escena no se aplica
Agregue transacciones en diferentes documentos. La base de datos Document-Director no admite transacciones entre documentos, y esta solución no debe utilizarse si es necesario.
3. Base de datos de almacén de columnas (almacén de columnas anchas/familia de columnas)
La base de datos de almacenamiento de columnas almacena datos en una familia de columnas, que almacena datos que a menudo se consultan juntos. Por ejemplo, si tenemos una clase Person, normalmente revisamos sus nombres y edades juntos en lugar de su salario. En este caso, el nombre y la edad se colocan en una familia de columnas y el salario está en otra familia de columnas.
Productos: Cassandra, HBase
有谁在使用:Ebay (Cassandra)-Instagram (Cassandra)-NASA (Cassandra)-Twitter (Cassandra y HBase)-Facebook (HBase)-Yahoo!(HBase)
El escenario aplicable
1. Registros. Dado que podemos almacenar datos en columnas diferentes, cada aplicación puede escribir información en su propia familia de columnas.
2. Plataforma de blog. Almacenamos cada información en una familia de columnas diferente. Por ejemplo, las etiquetas se pueden almacenar en una, las categorías pueden estar en una y los artículos pueden estar en otro.
La escena no se aplica
1. Si necesitamos una transacción ADID. Vassandra no admite transacciones.
2. Prototipado. Si analizamos la estructura de datos de Cassandra, encontramos que la estructura se basa en la forma en que esperamos que se consultan los datos. Al principio del diseño del modelo, era imposible predecir cómo se consultaría, y una vez que se cambió la consulta, tuvimos que rediseñar la familia de columnas.
Base de datos de Graph-Design
La base de datos de gráficos nos permite almacenar los datos de forma gráfica. La entidad se utiliza como verte y la relación entre las entidades se trata como una arista. Por ejemplo, si tenemos tres entidades, Steve Jobs, Apple y Next, habrá dos bordes "Fundado por" que conectarán Apple y Next con Steve Jobs.
产品: Neo4J-Gráfico Infinito-OrientDB
有谁在使用:Adobe (Neo4J)-Cisco (Neo4J)-T-Mobile (Neo4J)
El escenario aplicable
1. En algunos datos altamente errantes
2. Motor recomendado. Si graficamos los datos, será muy útil para la formulación de recomendacionesEl modelo de datos que no cabe en el escenario no es aplicable. El ámbito de aplicación de la base de datos de gráficos es muy pequeño, porque muy pocas operaciones implican todo el diagrama.
(Nota 0: Lo siguiente en inglés en este artículo:Kristóf KovácsPor. Bole Online - Tang Yuhua Traducción) Las diferencias entre las bases de datos NoSQL superan con creces las diferencias entre las dos bases de datos SQL. Esto significa que el arquitecto de software debería haber elegido una base de datos NoSQL adecuada al principio del proyecto. Para esta situación, aquí Cassandra、 Mongodb、 CouchDB、Redis、 Riak、 Membase、 Neo4j Y. HBase Se hicieron comparaciones.
(Nota 1: NoSQL: Un nuevo movimiento revolucionario de la base de datos, y NoSQL aboga por el uso del almacenamiento de datos no-d'iredic.) La arquitectura informática actual requiere un gran nivel de escala en el almacenamiento de datos, y NoSQL se compromete a cambiar eso. BigTable de Google y Dynamo de Amazon están utilizando actualmente la base de datos NoSQL. Ver.Términos noSQL。)
1. CouchDB
Idioma: Erlang
Características: consistencia de la base de datos, fácil de usar
Licencia: Apache
Protocolo: HTTP/REST
replicación de datos bidireccional,
procesamiento continuo o ad hoc,
Con la verificación de conflictos para el procesamiento,
Por lo tanto, se utiliza la replicación maestro-maestro (véase la nota 2)
MVCC - Las operaciones de escritura no bloquean las operaciones de lectura
Las versiones anteriores del archivo se pueden guardar
Diseño solo para choques (fiable)
La compresión de datos es necesaria de vez en cuando
Ver: Asignación/disminución integrada
Vista formateada: la lista se muestra
Se admite la validación de documentos del lado del servidor
Se admite la certificación
Actualizar en tiempo real como cambios
Se admite el procesamiento de datos adjuntos
Por lo tanto, CouchApps (aplicación js independiente)
Se requiere una biblioteca jQuery
El mejor escenario
Adecuado para aplicaciones con menos variación de datos, consultas predefinidas y estadísticas de datos. Para aplicaciones que requieren compatibilidad con la versión de datos.
Por ejemplo: CRM, sistema CMS. La replicación maestra es útil para implementaciones multisitio.
(Nota 2:replicación maestra:: es un método de sincronización de base de datos que permite que los datos se compartan entre un grupo de equipos y pueden ser actualizados dentro de un grupo por cualquier miembro del grupo.) )
2. Redis
Idioma: C/C
Características: Funcionamiento inusualmente rápido
Licencia: BSD
Protocolo: Clase Telnet
Bases de datos de memoria soportadas por el almacenamiento en disco duro,
Sin embargo, los datos se pueden intercambiar en el disco duro después de la versión 2.0 (tenga en cuenta que esta característica no se admite en versiones posteriores de 2.4!). )
Replicación maestro-esclavo (véase la Nota 3)
Aunque las tablas hash se utilizan con datos simples o indizadas por valores de clave, también se admiten operaciones complejas como ZREVRANGEBYSCORE.
INCR y co (adecuados para calcular límites o estadísticas)
Conjuntos de soporte (también union/diff/inter)
Lista de soporte (también admite colas; bloqueo de operaciones pop)
Compatibilidad con tablas hash (objetos con varios dominios)
Compatibilidad con conjuntos de clasificación (tabla de puntuación alta para consultas de rango)
Redis admite transacciones
Admite la configuración de datos en datos caducados (similar a un diseño de búfer rápido)
Pub/Sub permite a los usuarios implementar un mecanismo de mensajería
El mejor escenario
Para aplicaciones donde los datos cambian rápidamente y se puede cumplir el tamaño de la base de datos (para la capacidad de memoria).
Por ejemplo: precios de stock, análisis de datos, recopilación de datos en tiempo real, comunicación en tiempo real.
(Nota 3:Replicación de esclavo maestro: si solo un servidor controla todas las solicitudes de replicación al mismo tiempo, esto se denomina replicación de esclavo maestro y normalmente se aplica en clústeres de servidores que necesitan proporcionar alta disponibilidad.) )
3. MongoDB
Idioma: C
Características: Se conservan algunas características descriptas de SQL (consulta, índice).
Licencia: AGPL (iniciador: Apache)
协议:Personalizado, binario (BSON)
Replicación maestra/esclava (soporta la recuperación automática de errores, mediante la replicación de conjuntos)
Mecanismo de metralla incorporado
Se admiten consultas de expresiones Javascript
Cualquier función javascript se puede ejecutar en el lado del servidor
El soporte de actualización en el lugar es mejor que CouchDB
La asignación de memoria a archivo se utiliza en el almacenamiento de datos
El enfoque en el rendimiento supera los requisitos de funcionalidad
Se recomienda activar la función de registro (parámetros -journal)
En un sistema operativo de 32 bits, el tamaño de la base de datos está limitado a aproximadamente 2,5 Gb
Las bases de datos vacías representan aproximadamente 192Mb
Almacenar big data o metadatos con GridFS (no es un sistema de archivos real)
El mejor escenario
Adecuado para aplicaciones que requieren compatibilidad con consultas dinámicas, requieren índices en lugar de asignar/reducir entidades, requieren requisitos de rendimiento para bases de datos grandes y requieren CouchDB, pero están llenos de memoria porque los datos cambian con demasiada frecuencia.
Por ejemplo, iba a utilizar MySQL o PostgreSQL, pero debido a las barras predefinidas que vienen con ellos, no lo está.
4. Riak
Idiomas utilizados: Erlang y C, y algunos Javascript
Características: Tolerancia a fallos
Licencia: Apache
Protocolo: HTTP/REST o binario personalizado
Distribución y replicación ajustables (N, R, W)
Utilice JavaScript o Erlang para la validación y el soporte de seguridad antes o después de la operación.
Utilice JavaScript o Erlang para mapear/reducir
Recorrido de conexión y conexión: se puede utilizar como base de datos de gráficos
Index: Introduzca los metadatos que desea buscar (versión 1.0 que se admitirá pronto)
Compatibilidad con objetos de Big Data (Luwak)
Disponible en versiones de código abierto y Enterprise
Búsqueda de texto completo, índice, consulta a través del servidor de búsqueda Riak (versión beta)
Admite la supervisión SNMP para la replicación multisindémo Masterless y licencias comerciales
El mejor escenario
Adecuado para situaciones que desean utilizar una base de datos similar a Cassandra, pero no pueden controlar la hinchazón y la complejidad. Para situaciones en las que planea realizar replicación multisitio, pero requiere escalabilidad, disponibilidad y control de errores para un único sitio.
Algunos ejemplos son la recopilación de datos de ventas, los sistemas de control de fábrica, los requisitos estrictos de tiempo de inactividad y se pueden utilizar como un servidor web fácil de actualizar.
5. Membase
Idiomas utilizados: Erlang y C
Características: Compatible con Memcache, pero tanto con persistencia como con clustering de apoyo
Licencia: Apache 2.0
Protocolo: almacenamiento en caché y escalado distribuidos
Datos de indexación muy rápidos (200k plus/s) por valor de clave
Almacenamiento persistente en discos duros
Todos los nodos son únicos (replicación maestro-maestro)
Las unidades de caché similares a las cachés distribuidas también se admiten en la memoria
La E/S se reduce cuando los datos se escriben eliminando datos duplicados
Proporciona una muy buena interfaz web de gestión de clústeres
No es necesario detener el servicio de base de datos al actualizar el software
Admite grupos de conexiones y agentes de conexión de uso múltiple
El mejor escenario
Adecuado para aplicaciones que requieren acceso a datos de baja latencia, altos estándares de soporte y alta disponibilidad
Por ejemplo, el acceso a datos de baja latencia, como aplicaciones orientadas a anuncios, aplicaciones web de alta combinación, como juegos en línea (como Zynga).
6. Neo4j
Idioma: Java
Características: Base de datos gráfica basada en relaciones
Licencia: GPL, algunas de las cuales utilizan AGPL/Commercial Licensing
Protocolo: HTTP/REST (o incrustado en Java)
Se puede utilizar de forma independiente o integrada en aplicaciones Java
Tanto los nodos como los bordes del gráfico pueden tener metadatos
Muy bueno traer sus propias funciones de gestión web
La búsqueda de rutas se admite mediante una variedad de algoritmos
Los valores clave y las relaciones se indexan
Optimizar para operaciones de lectura
Transacciones de soporte (con Java api)
Utilice los gráficos Gremlin para recorrer el lenguaje
Soporte Groovy Guión
Soporte para backup en línea, monitoreo avanzado y soporte de alta confiabilidad para el uso de licencias COMERCIALes/AGPL
El mejor escenario
Adecuado para datos como gráficos. Esta es la diferencia más significativa entre Neo4j y otras bases de datos nosql.
Ejemplos: relaciones sociales, redes de transporte público, mapas y mapas de red
7. Cassandra
Idioma: Java
Características: Mejor soporte para mesas grandes y Dynamo
Licencia: Apache
Protocolo: Personalizado, binario (ahorros)
Distribución y replicación ajustables (N, R, W)
Se admite para consultar a través de columnas con valores clave para un rango
Funciones como tablas grandes: columnas, una colección de columnas para un atributo
Escribir más rápido que leer
Mapear/reducir tanto como sea posible basado en la plataforma distribuida Apache
Admito sesgo contra Cassandra, en parte debido a su hinchazón y complejidad, pero también debido a problemas de Java (configuración, excepciones, etc.)
El mejor escenario
Cuando se utilizan operaciones de escritura sobre lectura (registro) si cada configuración del sistema debe escribirse en Java (no se activa nadie para utilizar el software de Apache).
Por ejemplo, en la banca, las finanzas (que no son necesarias para las transacciones financieras, pero estas industrias exigen bases de datos más de lo que lo hacen) escriben más rápido que se lee, por lo que una característica natural es el análisis de datos en tiempo real
8. HBase
HBaseUtiliza con ghshephard.
Idioma: Java
Características: Soporta miles de millones de filas X millones de columnas
Licencia: Apache
Protocolo: HTTP/REST (compatible ThriftVéase la Nota 4)
Modelo después de BigTable
Mapa/reducción con una arquitectura distribuida
Optimizar las consultas en tiempo real
Puerta de entrada Thrift de alto rendimiento
El juicio previo de las operaciones de consulta se logra escaneando y filtrando en el lado del servidor
Admite XML, Protobuf y HTTP binario
Cascading, hive, and pig source and sink modules
Shell basado en Jruby (JIRB).
Los cambios de configuración y las actualizaciones más pequeñas se revierten
No hay un único punto de fracaso
Comparable al rendimiento de acceso aleatorio de MySQL
El mejor escenario
Para situaciones en las que se prefieren bigTables y requieren acceso aleatorio y en tiempo real a big data.
Por ejemplo, la base de datos de mensajería de Facebook (pronto llegarán casos de uso más genéricos).
Ir a "Descubrimiento" - "Echa un vistazo" navegar "Amigos están viendo"