Autor.. Liang TangFuente.. TechFlow Hoy estamos diseccionando un artículo clásico: Lecciones prácticas de la predicción de clics en anuncios en Facebook. Como se puede ver en el nombre de este artículo, el autor de este artículo es el equipo publicitario de Facebook.Esta es una combinación de GBDT y LR aplicación modelo en la predicción de la tasa de clics de anuncios, aunque ha pasado varios años, pero el método todavía no está completamente desactualizado, todavía hay algunas pequeñas empresas todavía en uso. Este artículo es muy, muy clásico, se puede decir que se recomienda, artículo de publicidad debe leer, dijo que es el sentido común de la industria no es demasiado. La calidad de este artículo es muy alta, el contenido también es relativamente básico, muy adecuado como el artículo introductorio de todos. Breve introducción. El artículo comienza con una breve introducción al estado de la publicidad en la industria de Internet en ese momento y el tamaño de Facebook en ese momento, cuando Facebook tenía 750 millones de usuarios activos diarios y más de un millón de anunciantes activos, por lo que la importancia de elegir los anuncios adecuados y eficaces para sus usuarios es enorme. Sobre esta base, el enfoque innovador de Facebook para combinar GBDT con un modelo de regresión lógica produce más del 3% en escenarios de datos del mundo real. En 2007 Google y Yahoo propusieron un mecanismo de cuota de anuncios de pujas en línea, pero Facebook y los escenarios de motores de búsqueda son diferentes, en escenarios de motores de búsqueda, los usuarios tendrán una clara intención de búsqueda. El motor filtra los anuncios en función de la intención de búsqueda del usuario, por lo que el conjunto de anuncios del candidato no será muy grande. Pero Facebook no tiene intenciones tan fuertes, por lo que facebook tiene un número mucho mayor de anuncios en sus candidatos, por lo que la presión y las demandas en el sistema son mayores.Pero este artículo no habla de contenido relacionado con el sistema.Concéntrese sólo en la última parte del modelo de clasificación。 Podemos ver que los anuncios en motores de búsqueda como Google y Yahoo son anuncios de búsqueda, y los de Facebook son anuncios recomendados. La mayor diferencia entre el segundo y el primero es que la lógica de los anuncios de recuperación es diferente, algo similar a la diferencia entre un sistema de referencia y un sistema de búsqueda.En el corazón de esto está la intención del usuario, y aunque el usuario no tiene fuertes intenciones cuando inicia sesión en Facebook, podemos extraer algunas intenciones débiles basadas en el comportamiento y hábitos de navegación anteriores del usuario. Por ejemplo, el usuario permanece en qué tipo de mercancías durante más tiempo, la mayoría de los clics en qué tipo de contenido y similar al filtrado colaborativo del comportamiento del usuario se abstraen en vectores. De hecho, hay mucho contenido, pero también muy valioso, se puede ver que Facebook en la escritura del papel se deja una mano.
Prácticas específicas Después de decir las tonterías que miramos a la práctica específica, la práctica específica que muchos estudiantes pueden haber escuchado que es la práctica GBDT-LR. Parece que se acabó una palabra, pero hay muchos detalles. Por ejemplo, ¿por qué usar GBDT, por qué GBDT puede funcionar? ¿Cuáles son los mecanismos en vigor aquí? Lo que está escrito en el papel es sólo superficial, y el pensamiento y el análisis de estos detalles es la clave. Porque la práctica en el papel no es universal, pero las implicaciones son a menudo universales. En primer lugar, la evaluación del modelo, el papel proporciona dos nuevos métodos de evaluación de modelos. Uno es Entropía Normalizada, y el otro es Calibración. Comencemos con la evaluación del modelo.
Normalized Entropy
Este indicador se utiliza comúnmente en escenarios del mundo real y se ve a menudo en el código y el papel de varios dioses. La traducción directa es el significado de la entropía normalizada, lo que significa que un poco cambiado, puede entenderse como la entropía cruzada después de la normalización. Se calcula por la relación entre el promedio de entropía cruzada de la muestra y la entropía cruzada del CTR de fondo.El CTR de fondo se refiere a la experiencia de los conjuntos de muestras de entrenamiento CTR, que se pueden entender como la tasa media de clics. Pero aquí hay que notar que no es la proporción de muestras positivas y negativas. Debido a que probamos el modelo antes de entrenarlo, como por proporción de muestra positiva y negativa de 1:3, el CTR de fondo aquí debe establecerse como la relación antes del muestreo. Supongamos que la relación es p, para que podamos escribir la fórmula NE:Por aquí.El valor de es, es decir, haga clic en 1, sin clic es -1. Esta es la fórmula en el papel, en la práctica, generalmente escribimos clic como 1, impresión (sin clic) como 0.
Calibration
La calibración se traduce en escalas de calibración medias, pero aquí creo que debe entenderse como una desviación de la línea de base. Este indicador es la relación entre el CTR promedio predicho por el modelo y el CTR de fondo, y cuanto más cerca esté la relación de 1, menor será la desviación de referencia de nuestro modelo y más cerca estará de la situación real.Esta fórmula se puede escribir como:
AUC
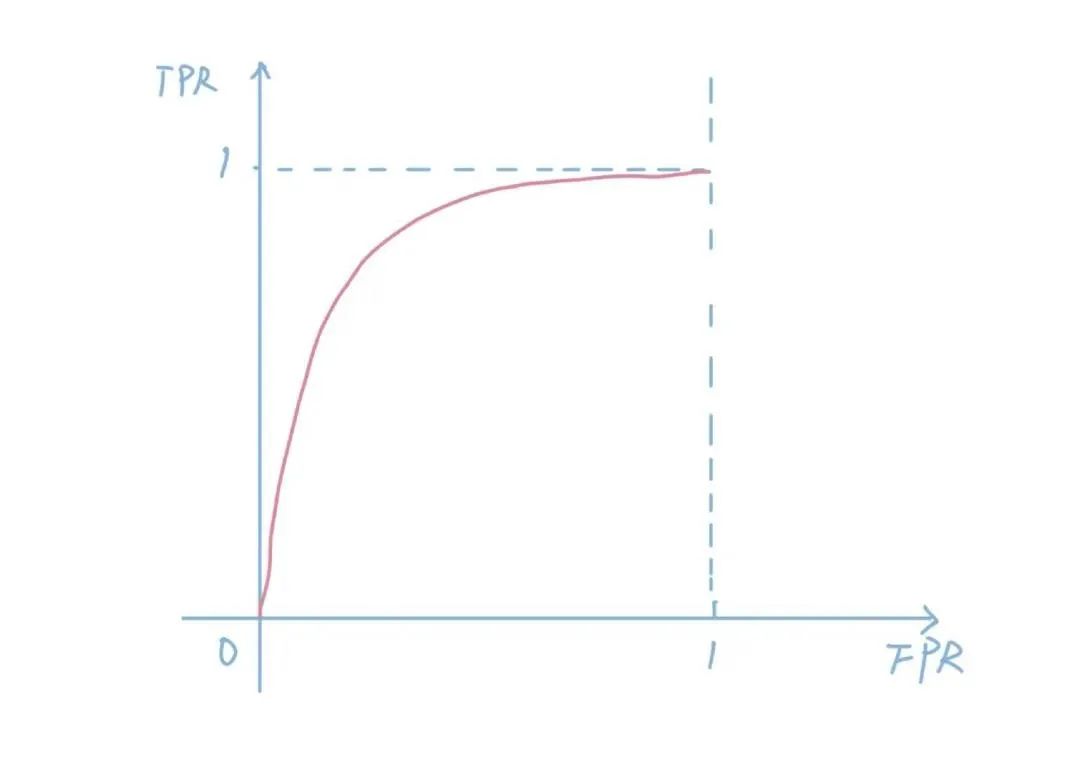
AUC es un indicador común y uno de los más utilizados en nuestra industria. AUC, como describimos en artículos anteriores, representa el Aera-Under-ROC, el área alrededor de la curva ROC. La curva ROC es una curva que consta de TPR (tasa postive verdadera) y FPR (tasa de falso positivo). Cuanto mayor sea el área de curva, más fuerte será la capacidad del modelo para distinguir entre muestras positivas y negativas, y en el escenario de clasificación CTR, si el modelo puede predecir la precisión no es la más importante, y la capacidad de filtrar muestras positivas es la más importante, por lo que AAUC es tan importante.Pero la AAUC no está exenta de sus inconvenientes, uno de los cuales figura en papel. Por ejemplo, si calibramos todos los CTR predichos por el modelo x2 y luego multiplicamos todas las predicciones por 0.5, el AAUC todavía no cambiará. Pero si miramos a NE, vemos que NE ha subido.El modelo combinadoFinalmente al juego, aunque este artículo dice muchos otros aspectos del contenido, pero todos sabemos que GBDT-LR es su foco. GBDT y LR nos son familiares, pero ¿cómo se unen?De hecho, el problema en sí está mal, el llamadoGBDT-LR no es una combinación de dos modelos, sino una transformación de características. Es decir, tenemos que pensar desde un punto de vista característico y no desde un modelo.El papel primero habla de dos métodos comunes para tratar las características, el primero de los cuales se llama bin, que significa bucket. Los ingresos, por ejemplo, son un rasgo de continuidad. Si lo ponemos en el modelo, lo que el modelo aprende es que tiene un peso, lo que significa que funciona linealmente. En un escenario del mundo real, sin embargo, puede que no sea lineal en absoluto. Por ejemplo, las marcas que les gustan a los ricos pueden ser completamente diferentes de los pobres, y esperamos que los modelos aprendan efectos no lineales. Un mejor enfoque sería dividir artificialmente esta característica, como las que tienen ingresos anuales inferiores a 30.000, 30.000 a 100.000, 100.000 a 500.000 y más de 500.000. En qué cubo cae, qué cubo está marcado con un valor de 1, de lo contrario se marca con 0.El segundo método se denomina combinación de características, que también se entiende bien, como si el género es una categoría y si los grupos de ingresos altos son una categoría. Entonces podemos organizar la combinación, usted puede conseguir hombres, bajos ingresos, hombres, altos ingresos, mujeres, bajos ingresos y altos ingresos cuatro categorías. Si se trata de una característica de continuidad, puede ser discreta mediante una estructura de datos como kd-tree. Podemos obtener más características cruzando las características de categoría, pero estas características no siempre son útiles, algunas pueden no ser útiles, y algunas pueden ser útiles, pero los datos son escasos. Así que si bien esto puede producir muchas características, requiere detección manual, muchas de las cuales no son válidasDebido a que la cantidad de filtrado manual de características es demasiado y los beneficios no son altos, los ingenieros comenzaron a pensar en la pregunta: ¿Hay alguna manera de filtrar automáticamente las características? Ahora todos sabemos que las redes neuronales se pueden utilizar para el corte y cribado automático de funciones, pero las redes neuronales no aumentaron en ese momento, por lo que sólo se pueden hacer manualmente. Para resolver este problema, los ingenieros en ese momento se le ocurrió GBDT.Es por eso que hay GBDT-LR, echemos un vistazo a esta imagen:Vamos a revisar brevemente el modelo de GBDT, que es primero un modelo de bosque de varios árboles. Para cada muestra, cae en uno de los nodos hoja de cada subárbol en el momento de la predicción. Así que podemos usar GBDT para mapear entidades, echemos un vistazo a un ejemplo:En el ejemplo anterior, GBDT tiene tres subárboles, el primero de los cuales tiene tres nodos hoja. Nuestra muestra cae al primero, por lo que el resultado del primer subárbol es 1, 0, 0, el segundo subárbol también tiene 3 nodos, la muestra cae en el segundo nodo, por lo que el resultado del uno-caliente es 0, 1, 0, el resultado del tercer subárbol es el resultado del tercer subárbol.Así que terminamos fusionando los vectores de estos árboles y obtenemos un nuevo vector: 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, y este vector es la entrada a nuestro modelo LR.
Analicemos los detalles, en primer lugar, para que sean claros, GBDT solo se utiliza para la conversión y el procesamiento de características, y sus predicciones no son importantes.Mediante el uso de GBDT, hemos completado las dos operaciones mencionadas en este momento, transformando la característica de continuidad en una entidad discreta y completando automáticamente la intersección de las entidades.Porque para cada subárbol, es esencialmente un árbol de decisión implementado por un algoritmo CART, lo que significa que el vínculo de la raíz al nodo hoja representa una regla potencial. Así que podemos aproximar el uso de GBDT en lugar de la extracción manual de reglas y el procesamiento de características.
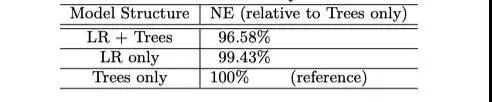
Resultados. Por último, echemos un vistazo a los resultados, el documento original llevó a cabo tres conjuntos de experimentos, respectivamente, sólo LR, sólo GBDT y GBDT-LR para comparar. Medido por sus respectivos NE, usando el árbol más grande del NE-solamente como referencia, usted puede ver que el NE en el grupo GBDT-LR disminuyó en 3.4%. Publicamos los resultados del documento:
Sin embargo, este resultado es bastante inteligente, porque el contraste es NE, lo que significa que la entropía cruzada ha disminuido. Pero la situación de las AAUC no se conoce, y no se dice en el periódico. Y esta disminución se basa en los mayores resultados de NE, con un poco de exageración artificial. Por supuesto, este es también un medio común de papel, tenemos un número en mente. La naturaleza en tiempo real de los datos
Además de las innovaciones en modelos y características, este documento explora el papel de la erranteidad de los datos.
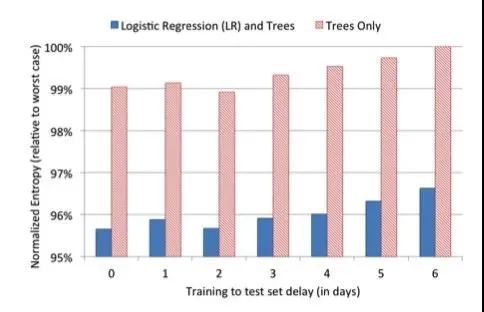
Para verificar la relación entre la actualización de datos y el rendimiento del modelo, el papel selecciona un fragmento de datos para entrenar los dos modelos, solo árbol y GBDT-LR y, a continuación, utiliza los dos modelos para predecir los datos para los próximos 1 a 6 días, trazando la situación general:En este diagrama, el eje horizontal es el número de días para predecir la distancia de los datos de entrenamiento, y el eje vertical es el NE del modelo.Cuanto menor sea el NE, mejor será el efecto del modelo, y de la figura anterior podemos ver que la diferencia entre los resultados del sexto día y el NE en el 0o día es de aproximadamente el 1%.Esto significa que simplemente mantener la frescura de los datos nos permite obtener un aumento del 1%.Es por eso que las empresas hacen aprendizaje en línea.
online learning
En la siguiente parte, el documento también nos presenta algunos de los detalles del aprendizaje en línea.Algunos de ellos están desactualizados, o no son universales, y he elegido algunas listas típicas y representativas.
La ventana de tiempo
En nuestro proceso de recopilación de datos de entrenamiento, hacer clic es más explícito porque hacer clic tiene un comportamiento específico, pero la imppresión (exposición) no lo es. Debido a que el usuario no hizo clic en esto no es un acto, por lo que no podemos determinar si el usuario no quiere apuntar o esperar un poco más. Es una práctica más común mantener una ventana de tiempo que especifique una hora, y si el usuario ve que el anuncio no ha hecho clic dentro del tiempo especificado, se considera un evento que no es clic.Pero es fácil ver que hacerlo es problemático porque el usuario puede no responder, o puede que no haya respondido durante un tiempo y no haya hecho clic. Puede ser que el tiempo haya pasado y el usuario haga clic en la situación. En este caso, la imppresión se ha registrado como una muestra negativa, por lo que haga clic en la muestra positiva resultante no puede encontrar la imppresión correspondiente. Podemos calcular una proporción de cuántos clics se pueden encontrar para encontrar imppresión, que se llama cobertura de clics, cobertura de tasa de clics.¿Es más larga la ventana, mejor? De hecho, no lo es, porque la ventana es demasiado larga puede llevar a poner algunos no hacer clic se considera que es clic. Por ejemplo, por ejemplo, un elemento, el usuario no está satisfecho la primera vez que navega, por lo que no tiene sentido. Después de un tiempo, cuando el usuario volvió a verlo, cambió de opinión y hizo clic. Entonces es razonable pensar en el primer punto-sin comportamiento como una muestra negativa y el segundo comportamiento como una muestra positiva. Si nuestra ventana de tiempo se establece muy larga, se considerará una muestra de clic. Así que la ventana de tiempo al final debe establecerse por mucho más tiempo, este es un parámetro que necesita ser ajustado, no puede dar palmaditas en la cabeza para decidir.
Arquitectura.
El streaming es un método comúnmente utilizado de procesamiento de datos en la industria, llamado streaming. Se puede entender simplemente como una cola, es decir, una cola. Pero cuando se produce un clic necesitamos encontrar la muestra de imppresión correspondiente y cambiarla a una muestra positiva, por lo que también necesitamos buscar la funcionalidad. Esto significa que también necesitamos un mapa hash para registrar nodos en la cola.Cuando recopilamos suficientes datos o datos de muestra durante un período de tiempo especificado, usamos los datos de la ventana para entrenar el modelo. Cuando se entrena el modelo, se inserta en el sistema de clasificación y los archivos de modelo que se deben llamar para la clasificación se actualizan en tiempo real, con el fin de lograr el objetivo de la formación en tiempo real en línea. Echemos un vistazo a su diagrama de arquitectura:Ranker es un sistema de clasificación que ordena los anuncios candidatos y los muestra a los usuarios, y proporciona los datos de características de esos anuncios a joiner en línea, el sistema de procesamiento de características. Cuando un usuario hace clic en un anuncio, los datos en los que se haido clic también se pasan a Joner. Joiner asocia los datos de clic del usuario con los datos transmitidos por Ranker, que luego transmite los datos al sistema Trainer para el entrenamiento del modelo. También hay un detalle aquí, es decir, ¿cómo nos relacionamos entre nosotros en el joyero? Dado que un usuario puede tener datos para ver un anuncio más de una vez, el mismo anuncio puede actualizarse para verlo varias veces. Por lo tanto, no es posible asociarse directamente con un IDENTIFICADOR de usuario o un identificador de anuncio, también necesitamos un identificador relacionado con el tiempo. Este identificador se denomina requestid y cada vez que un usuario actualiza una página, el requestid se actualiza para garantizar que incluso si el usuario actualiza la página, podemos asociar correctamente los datos.
Análisis de características
Por último, se adjunta un análisis de las características al documento. Aunque no sabemos exactamente qué características utilizan todos, el contenido de estos análisis sigue siendo útil para nosotros.
Características del comportamiento o características de contexto
En el escenario estimado por el CTR, hay dos características principales, una es la característica del contexto y la otra es la característica del comportamiento histórico del usuario. La llamada característica contextual es en realidad un gran concepto. La información sobre la escena actual, como la información sobre el anuncio que se muestra, la propia información del usuario y la hora en ese momento, el contenido de la página, la ubicación del usuario, etc., se puede considerar información contextual. Las características de comportamiento histórico también se entienden bien, es decir, el comportamiento que los usuarios han generado previamente dentro de la plataforma.El papel se centra en la importancia de las características de comportamiento del usuario, en las que las características se invierten según la importancia, y luego se calcula la proporción de características de comportamiento histórico del usuario en las características importantes de topK. En el modelo LR, la importancia de la entidad es equivalente al peso de la posición correspondiente, y el resultado es el siguiente:Como podemos ver en los resultados de la figura anterior, las características de comportamiento histórico del usuario ocupan un peso muy grande en el conjunto. Solo dos de las fuentes de top20 son características contextuales. Esto también está en línea con nuestra comprensión de que la calidad del contenido que entregamos es mucho menos importante que lo que les gusta a los usuarios. Y los datos que han generado comportamiento en el historial del usuario son un muy buen reflejo de las preferencias del usuario.
Análisis de importancia
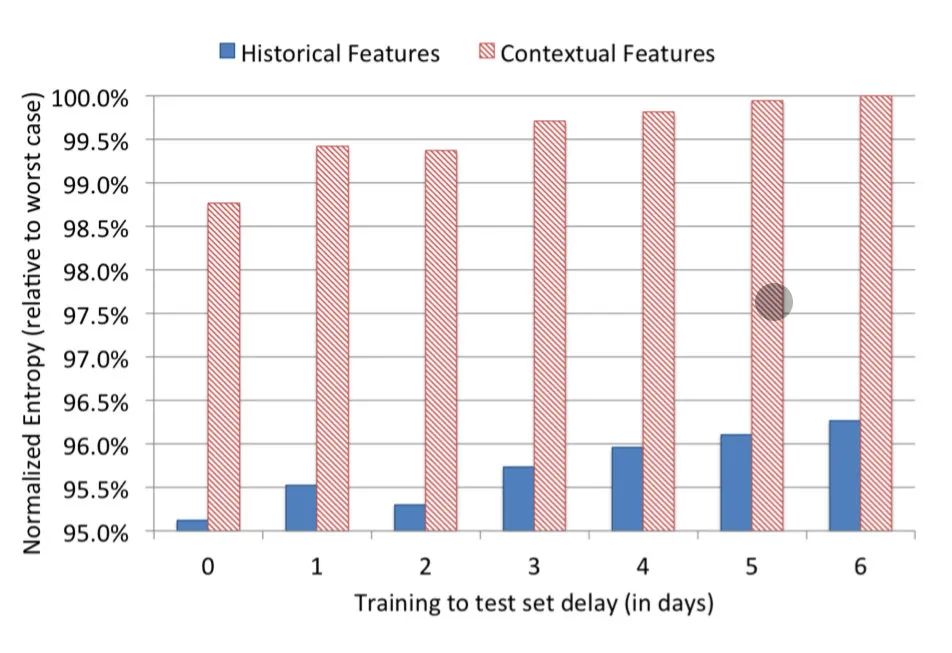
Además de analizar la importancia de las características, el papel experimenta con la predicción de un solo tipo de entidad para comparar el rendimiento del modelo. Los resultados del experimento son los siguientes:La barra roja de la imagen anterior muestra los resultados de entrenamiento que solo utilizan características de contexto, y azul oscuro son los resultados de entrenamiento que solo utilizan características de comportamiento del usuario. A partir de este resultado, está claro que el rendimiento del modelo entrenado utilizando características de comportamiento es al menos 3,5 puntos mejor que el uso de características de contexto, que ya es una brecha muy grande. Por lo tanto, también podemos concluir que las características de comportamiento del usuario son más útiles que las características contextuales.Además, en el documento se examinan los efectos del muestreo negativo hacia abajo (muestreo negativo) y el submuestreo (muestreo secundario) en el rendimiento del modelo. QueEl muestreo secundario demuestra que la cantidad de datos de entrenamiento se compara positivamente con el efecto general del modelo, es decir, cuanto mayor sea la cantidad de datos de entrenamiento, mejor será el efecto del modelo。 El muestreo negativo también es útil para mejorar la eficacia del modelo, que es el método habitual en los escenarios actuales de publicidad y recomendación.


 Breve introducción.
Breve introducción. Prácticas específicas
Prácticas específicas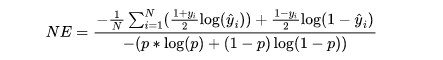
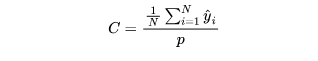
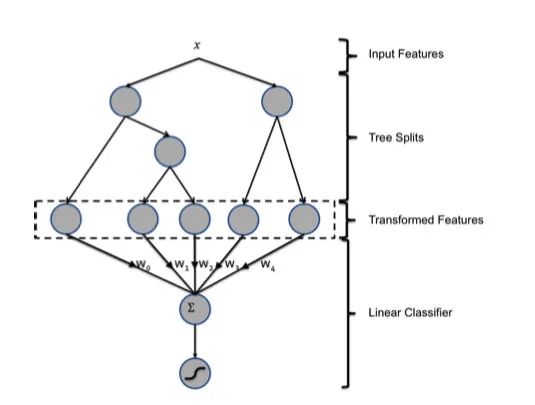
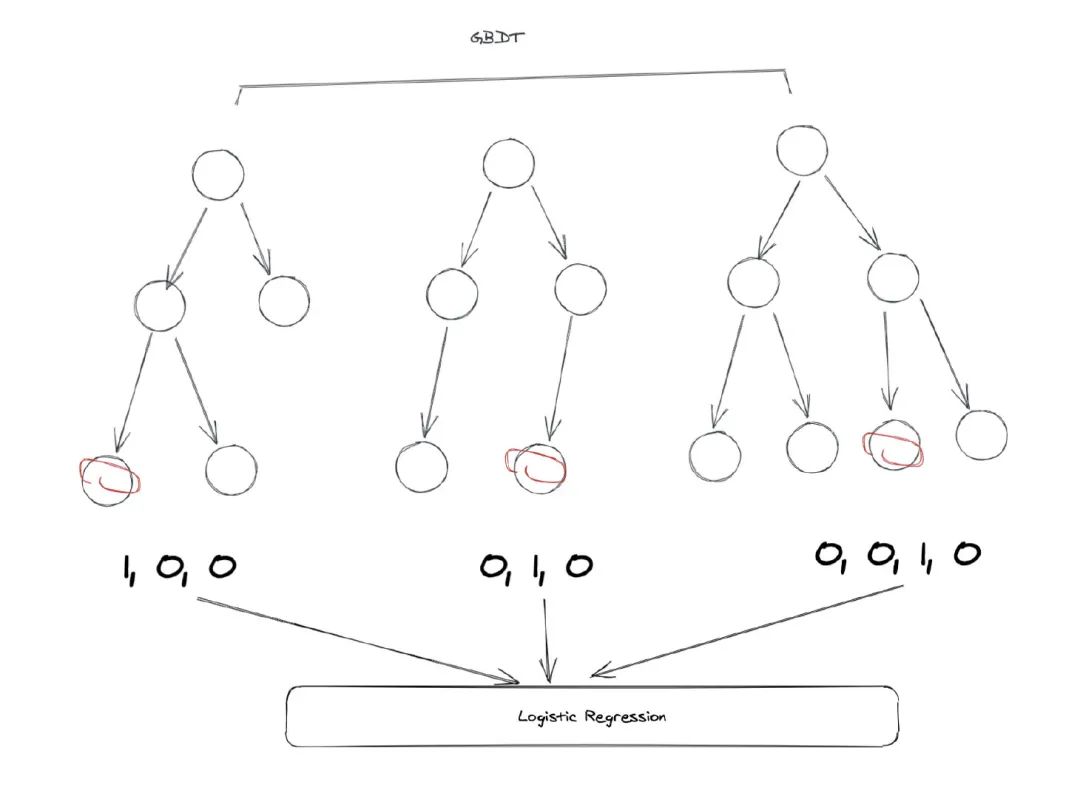 En el ejemplo anterior, GBDT tiene tres subárboles, el primero de los cuales tiene tres nodos hoja. Nuestra muestra cae al primero, por lo que el resultado del primer subárbol es 1, 0, 0, el segundo subárbol también tiene 3 nodos, la muestra cae en el segundo nodo, por lo que el resultado del uno-caliente es 0, 1, 0, el resultado del tercer subárbol es el resultado del tercer subárbol.
En el ejemplo anterior, GBDT tiene tres subárboles, el primero de los cuales tiene tres nodos hoja. Nuestra muestra cae al primero, por lo que el resultado del primer subárbol es 1, 0, 0, el segundo subárbol también tiene 3 nodos, la muestra cae en el segundo nodo, por lo que el resultado del uno-caliente es 0, 1, 0, el resultado del tercer subárbol es el resultado del tercer subárbol.

 online learning
online learning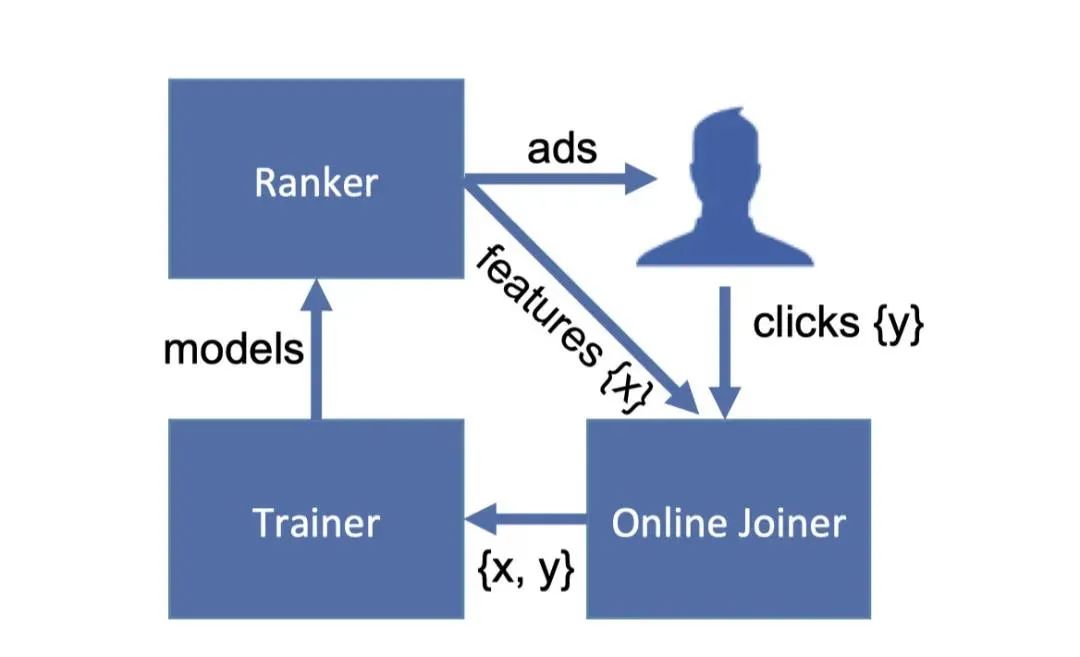
 Análisis de características
Análisis de características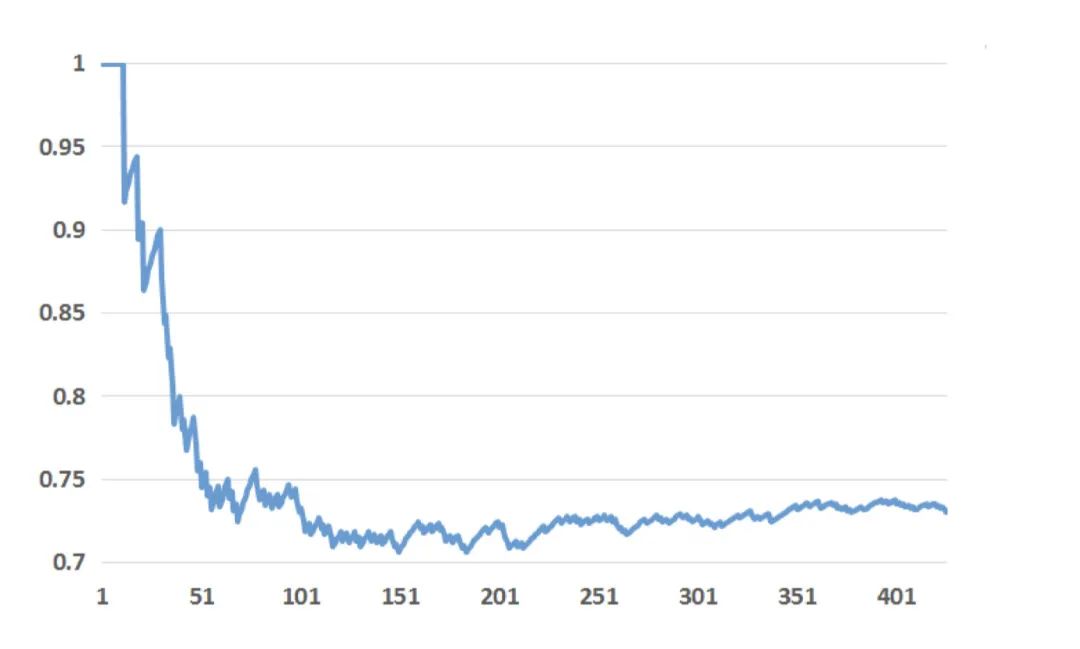


Ir a "Descubrimiento" - "Echa un vistazo" navegar "Amigos están viendo"